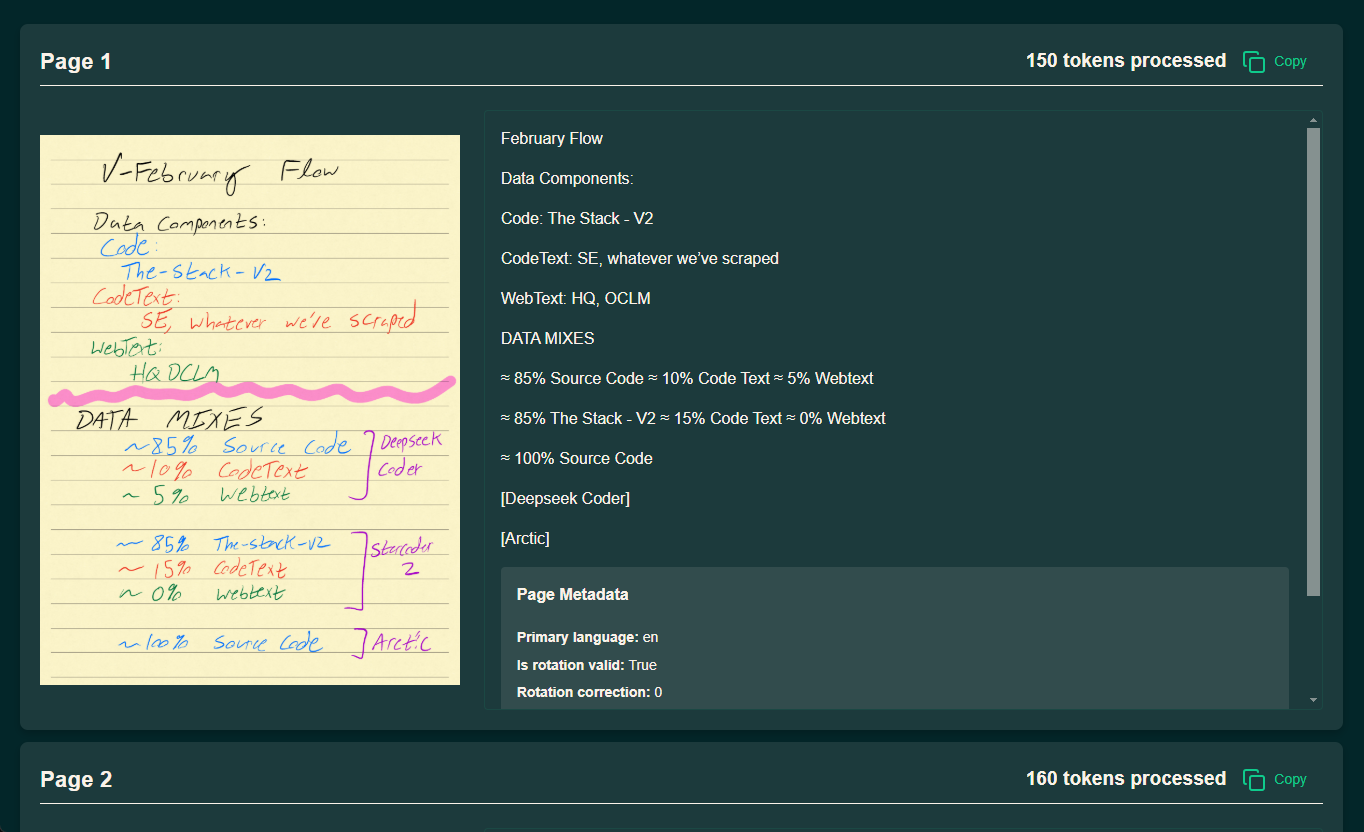
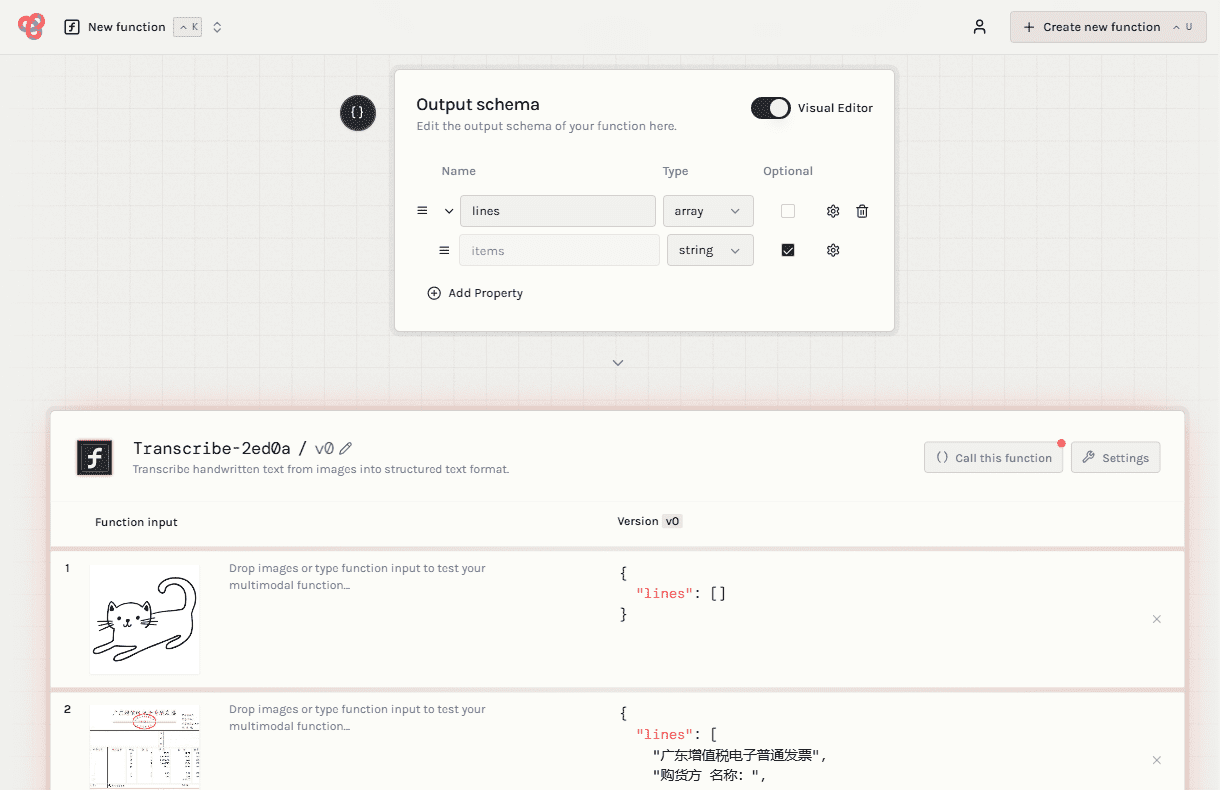
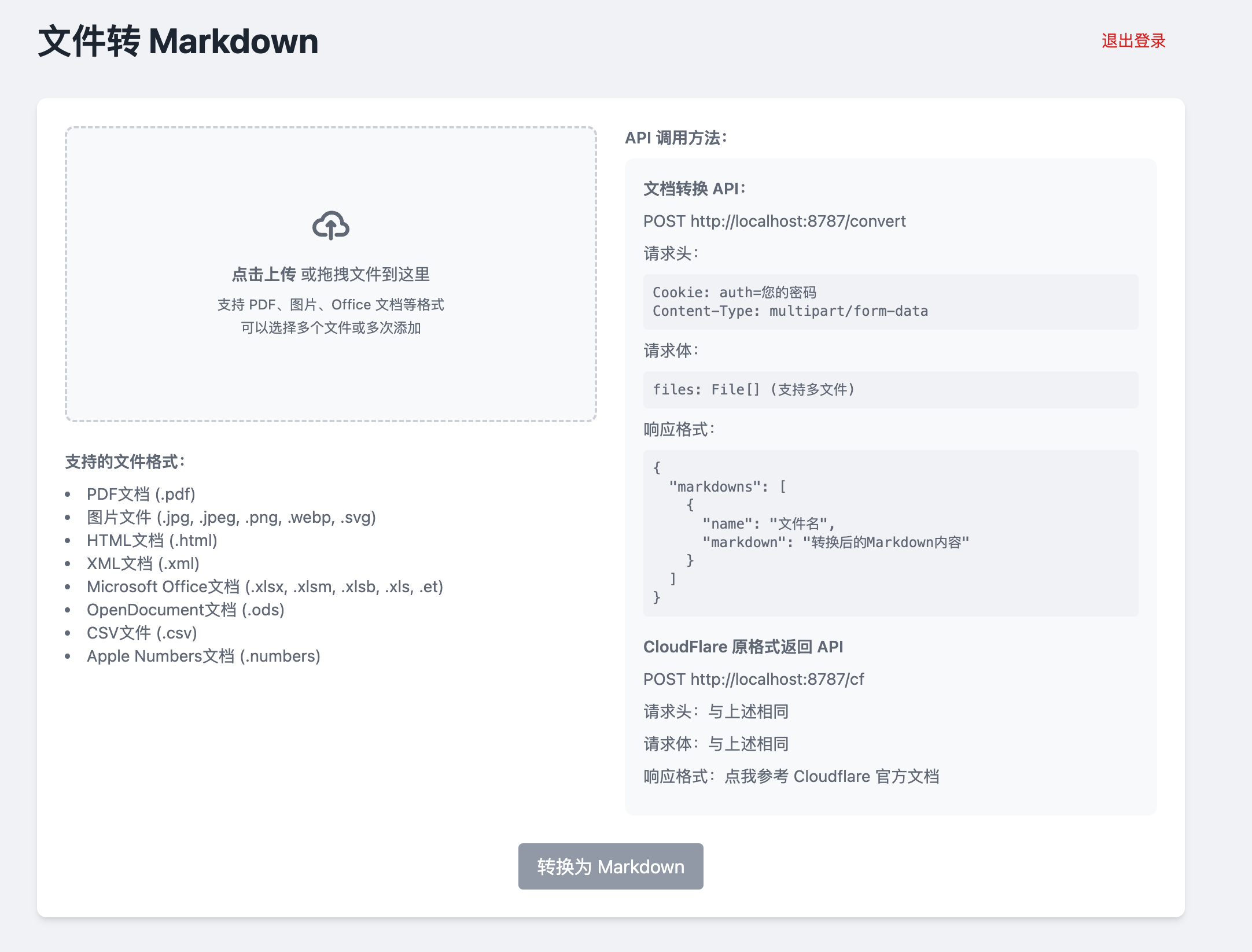
UnDatas.IO: servicio API para el análisis preciso de diversos tipos de datos no estructurados (de pago)
Introducción completa UnDatas.IO es una plataforma centrada en el análisis sintáctico y el tratamiento de datos no estructurados. Utiliza tecnología avanzada para reconocer automáticamente el diseño de los documentos y clasificar tablas, imágenes, fórmulas y texto, simplificando enormemente el proceso de tratamiento de datos. La plataforma no sólo ahorra mucho tiempo en la clasificación de datos...