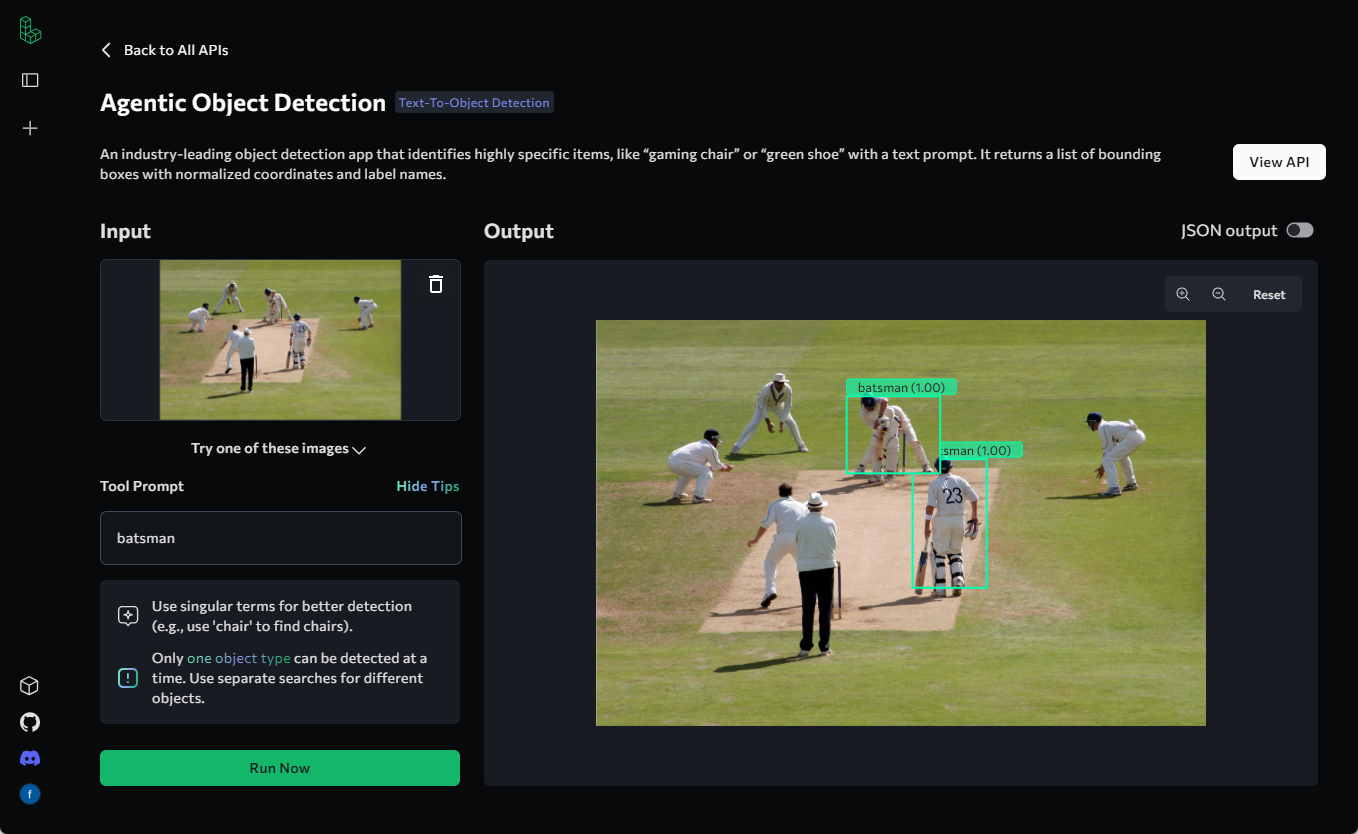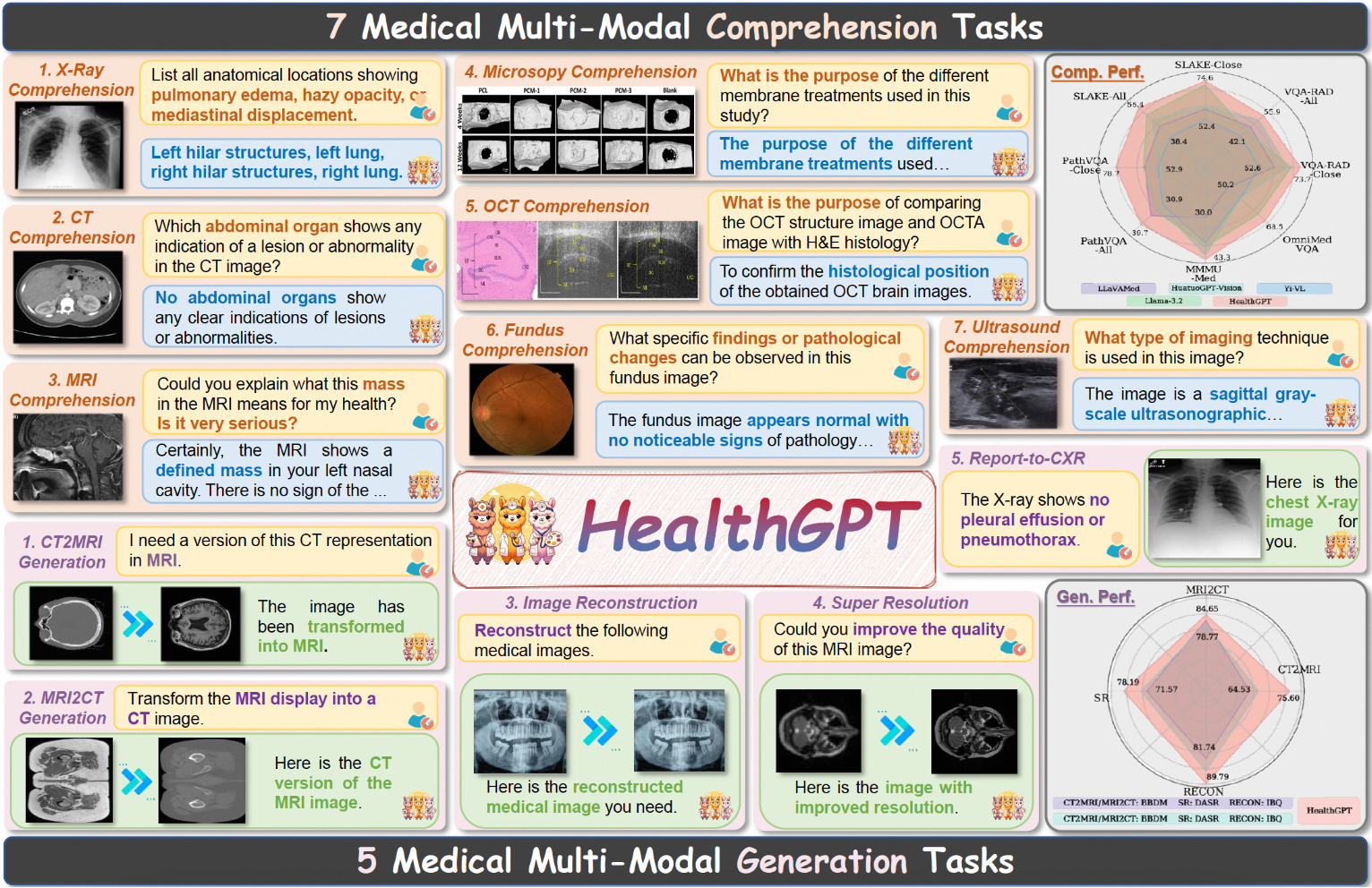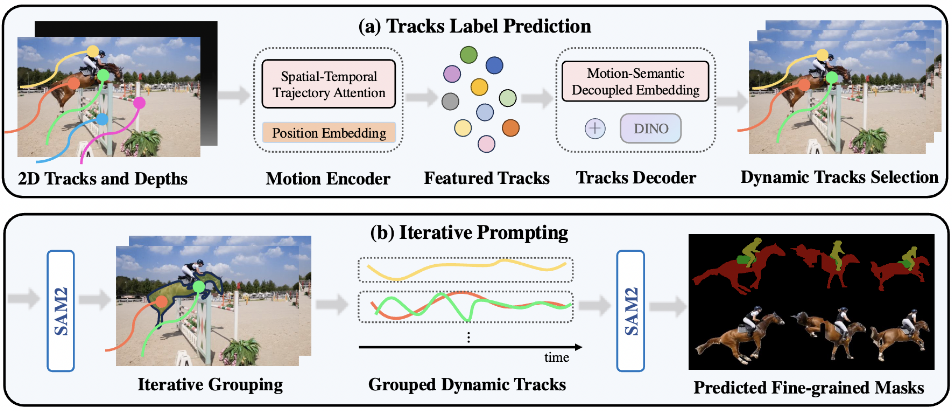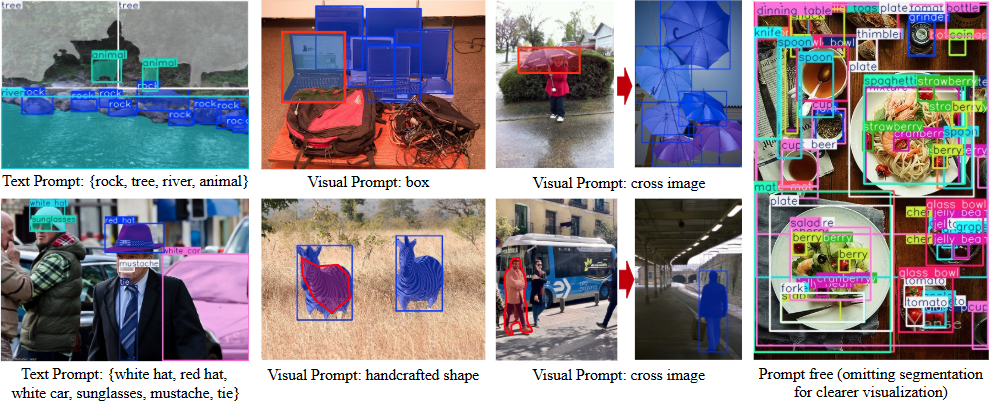
Video Analyzer: analysiert Videoinhalte und erstellt detaillierte Beschreibungen
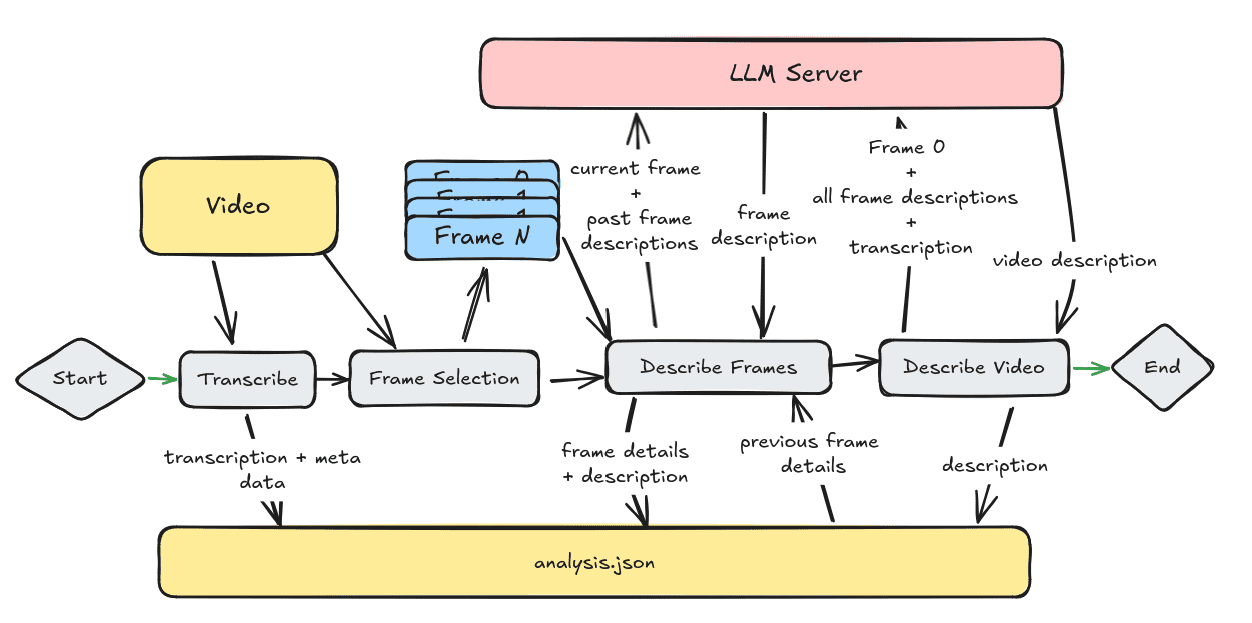
Comprehensive Introduction Video Analyzer ist ein umfassendes Videoanalysetool, das Computer Vision, Audiotranskription und Techniken zur Verarbeitung natürlicher Sprache kombiniert, um detaillierte Beschreibungen von Videoinhalten zu erstellen. Das Tool transkribiert Audioinhalte, indem es Schlüsselbilder aus dem Video extrahiert...