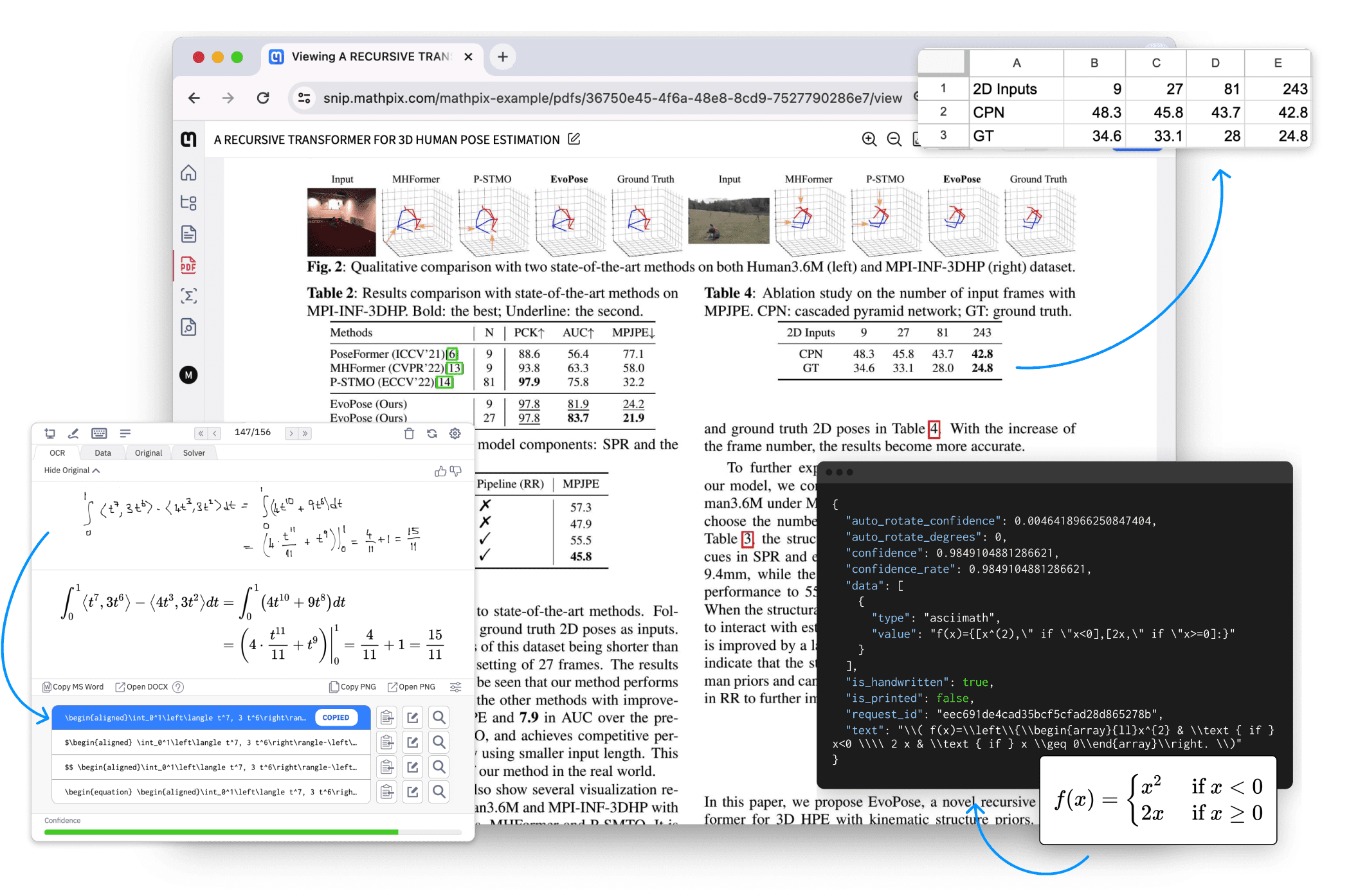
Introdução abrangente O MinerU é uma ferramenta de extração de dados de código aberto desenvolvida pela equipe do OpenDataLab no Laboratório de Inteligência Artificial de Xangai, com foco na extração eficiente de conteúdo de documentos PDF complexos, páginas da Web e eBooks. Ele é capaz de obter PDFs multimodais contendo imagens, fórmulas, tabelas e outros elementos...