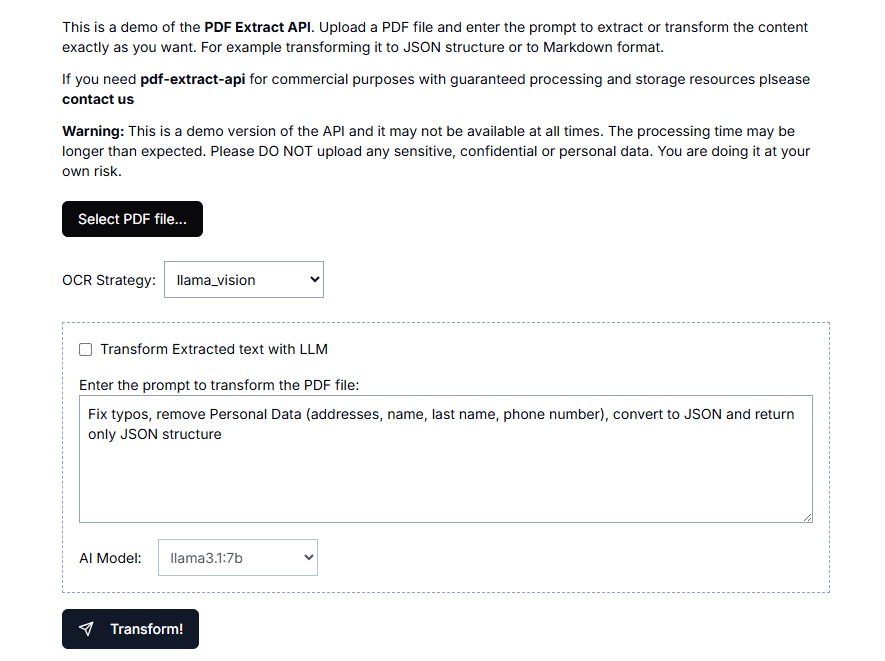
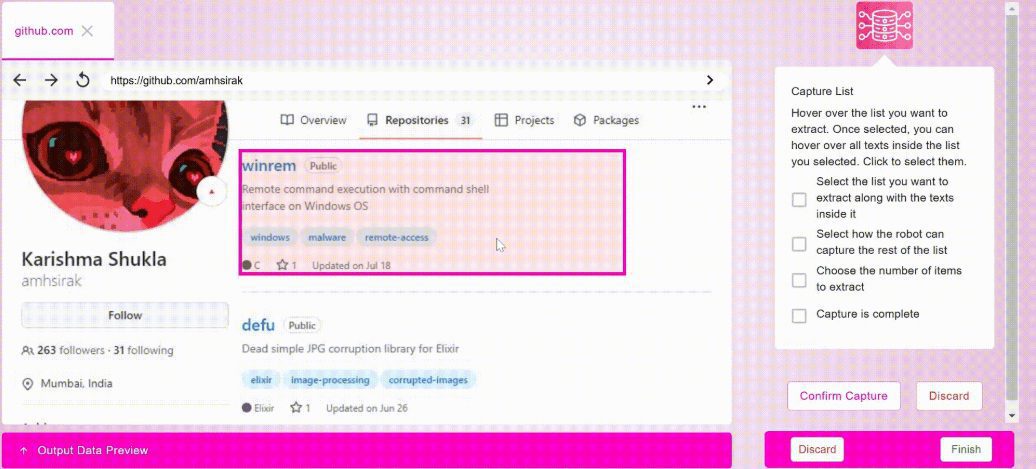
Introdução abrangente O MinerU é uma ferramenta de extração de dados de código aberto desenvolvida pela equipe do OpenDataLab no Laboratório de Inteligência Artificial de Xangai, com foco na extração eficiente de conteúdo de documentos PDF complexos, páginas da Web e eBooks. Ele é capaz de obter PDFs multimodais contendo imagens, fórmulas, tabelas e outros elementos...
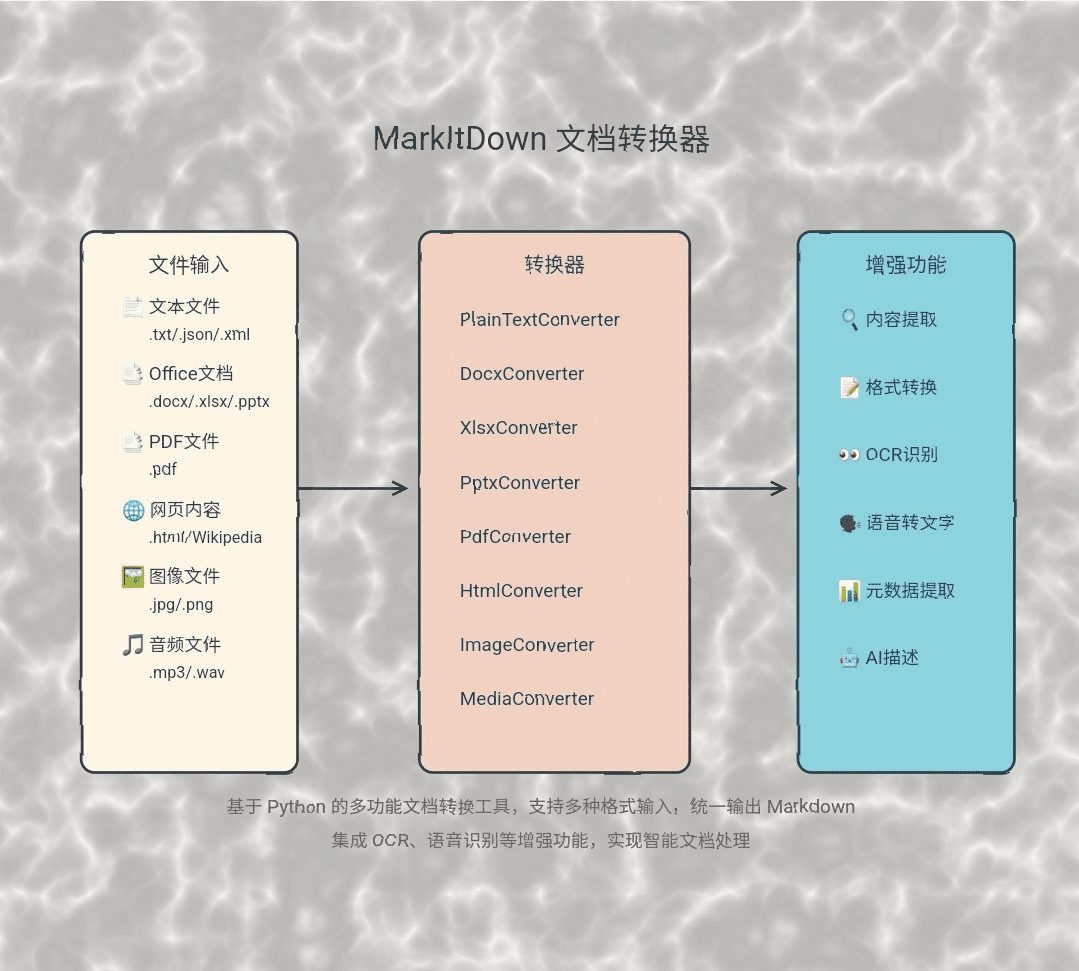
Introdução geral O MarkItDown é uma ferramenta Python desenvolvida pela Microsoft e projetada para converter vários arquivos e documentos de escritório no formato Markdown. A ferramenta é compatível com uma ampla variedade de tipos de arquivos, incluindo PDF, PowerPoint, Word, Excel, diagramas...
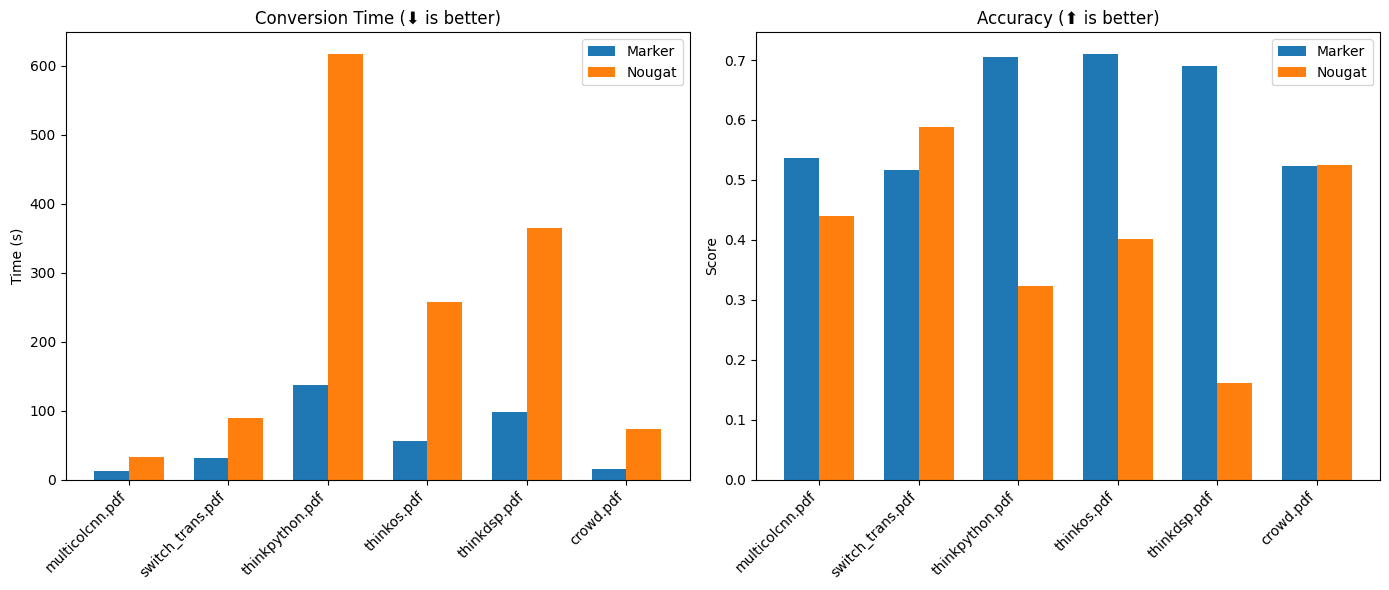
Descrição geral O Marker é uma ferramenta de processamento de documentos baseada em aprendizagem profunda, projetada para converter arquivos PDF para o formato Markdown com rapidez e precisão. Ele oferece suporte a uma ampla variedade de tipos de documentos e é especialmente otimizado para a conversão de livros e artigos científicos.
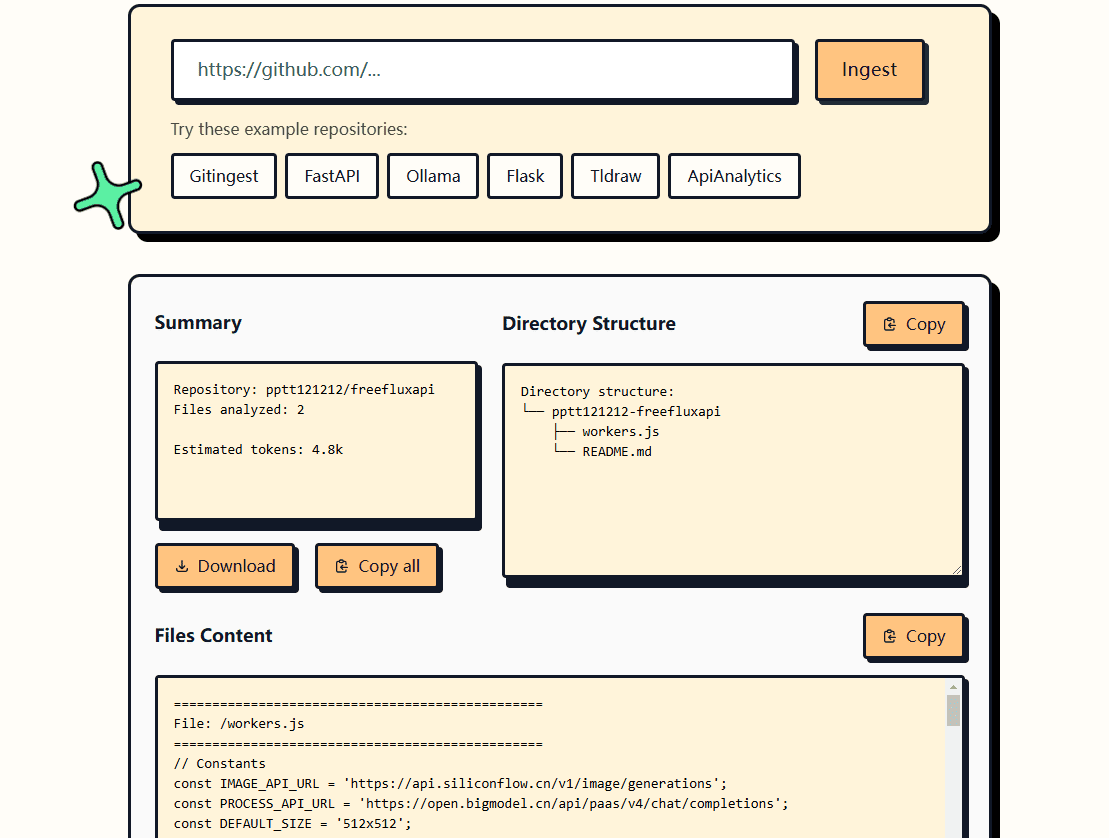
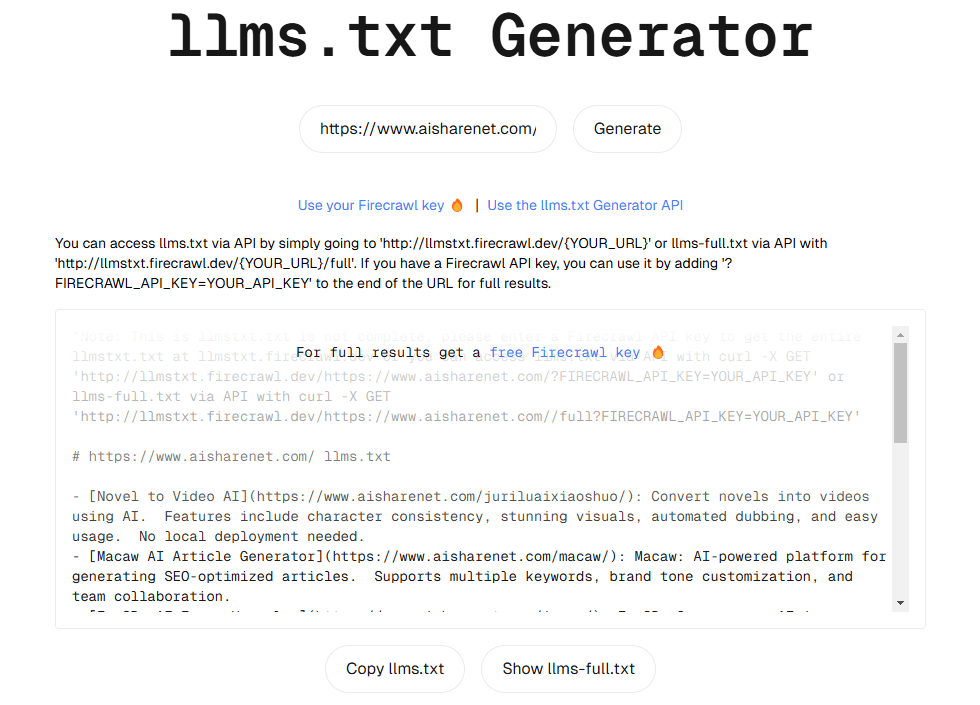
Introdução abrangente O llmstxt-generator é uma ferramenta profissional de extração e integração de conteúdo da Web dedicada à preparação de conjuntos de dados textuais de alta qualidade para treinamento e inferência em modelagem de linguagem ampla (LLM). A ferramenta foi desenvolvida pela Mendable AI usando o @firec...
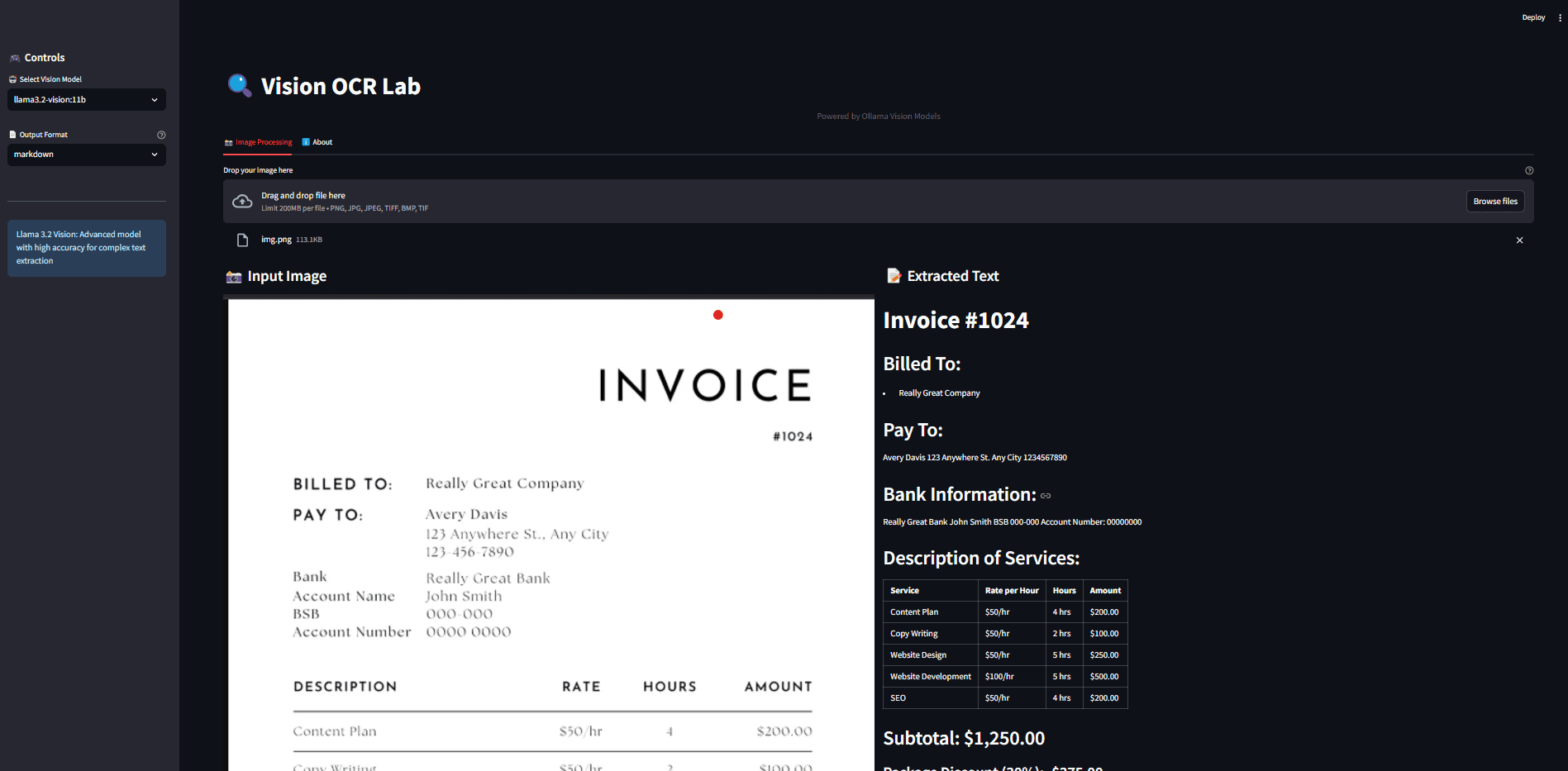
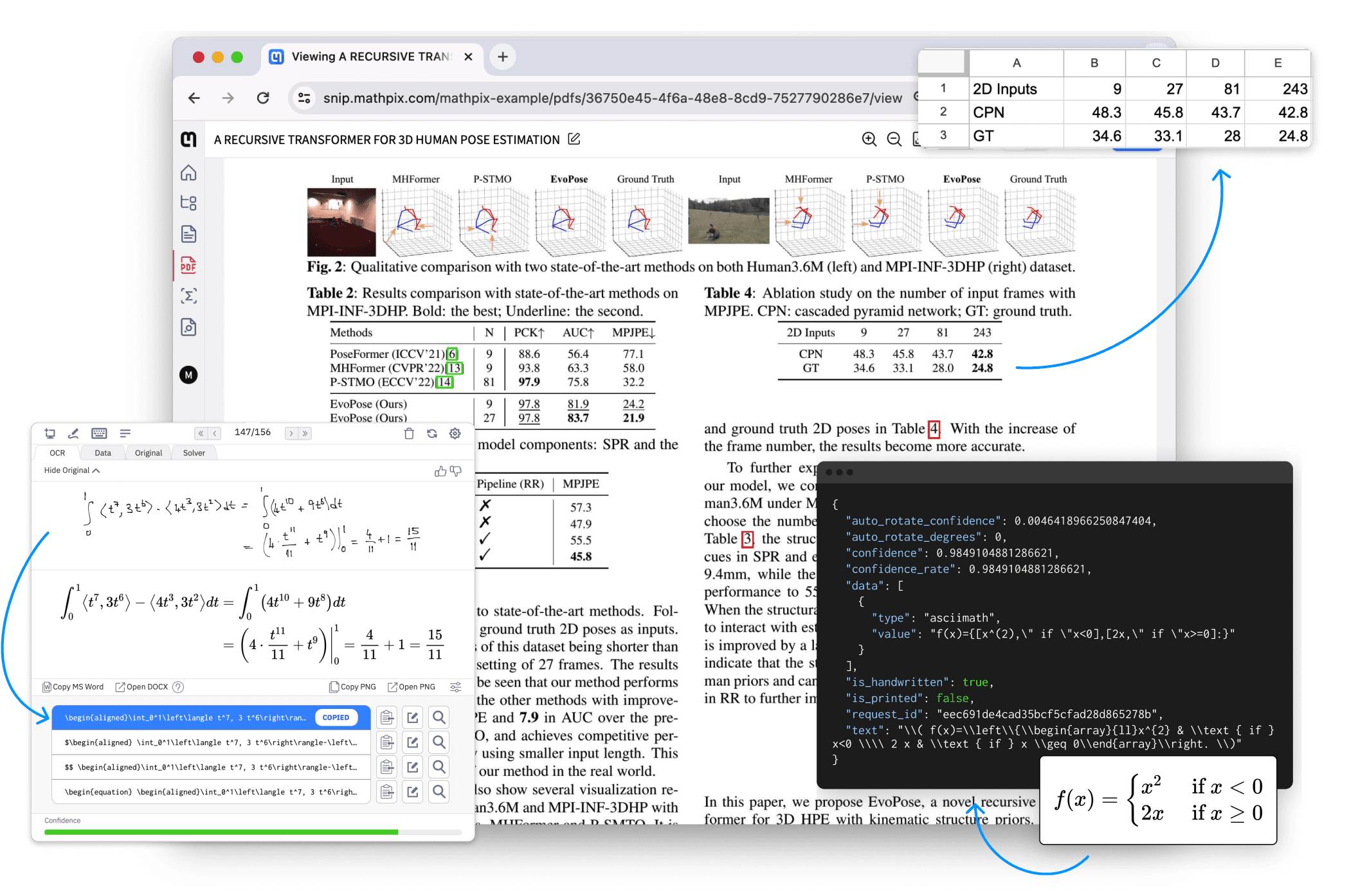
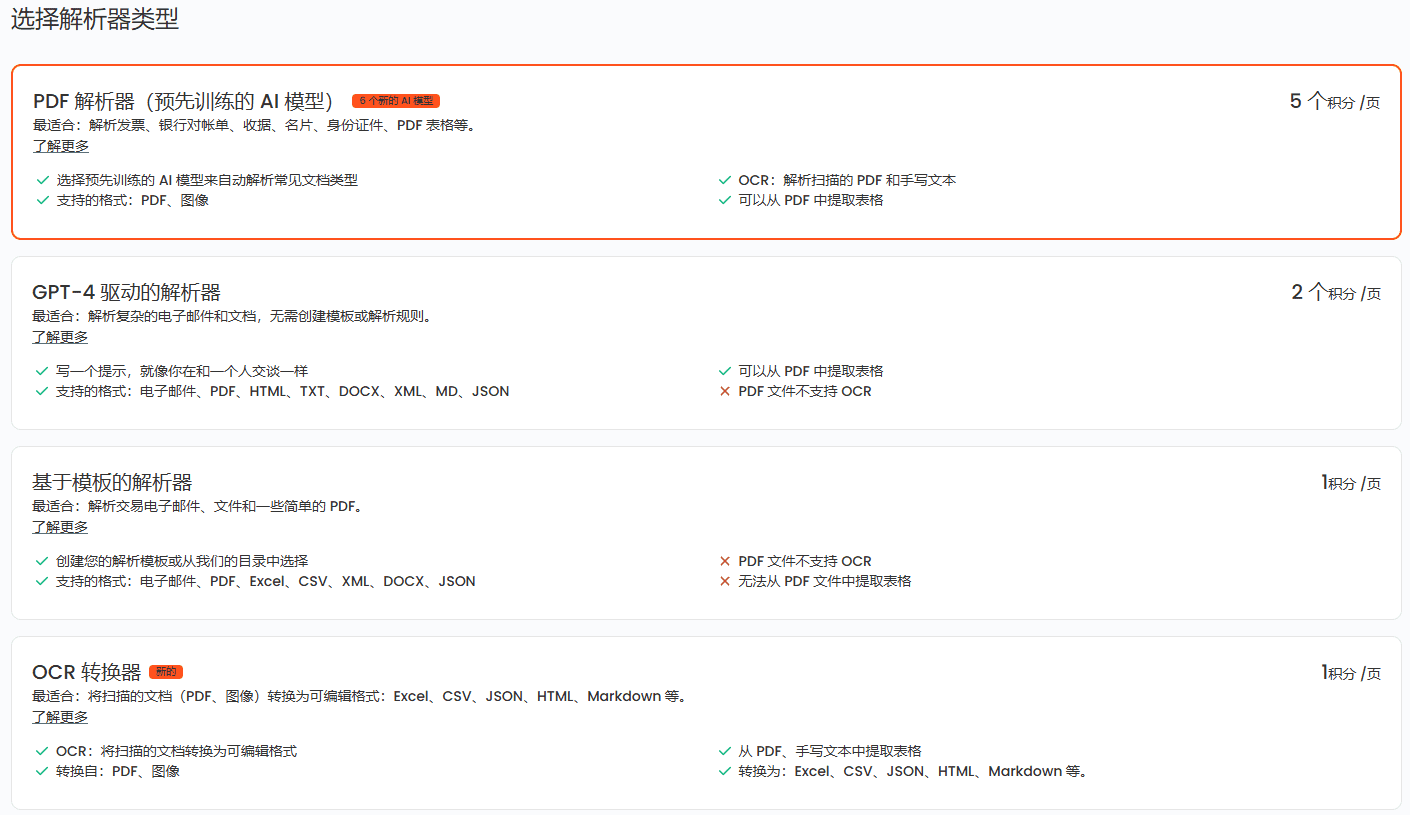
Introdução abrangente O Doc2X é uma poderosa ferramenta de conversão e reconhecimento de fórmulas de imagens de documentos, comprometida em fornecer soluções eficientes e inteligentes de processamento de documentos. Quer se trate de um trabalho de pesquisa acadêmica, um livro didático, um documento corporativo ou um relatório financeiro, o Doc2X pode identificar com precisão tabelas e...