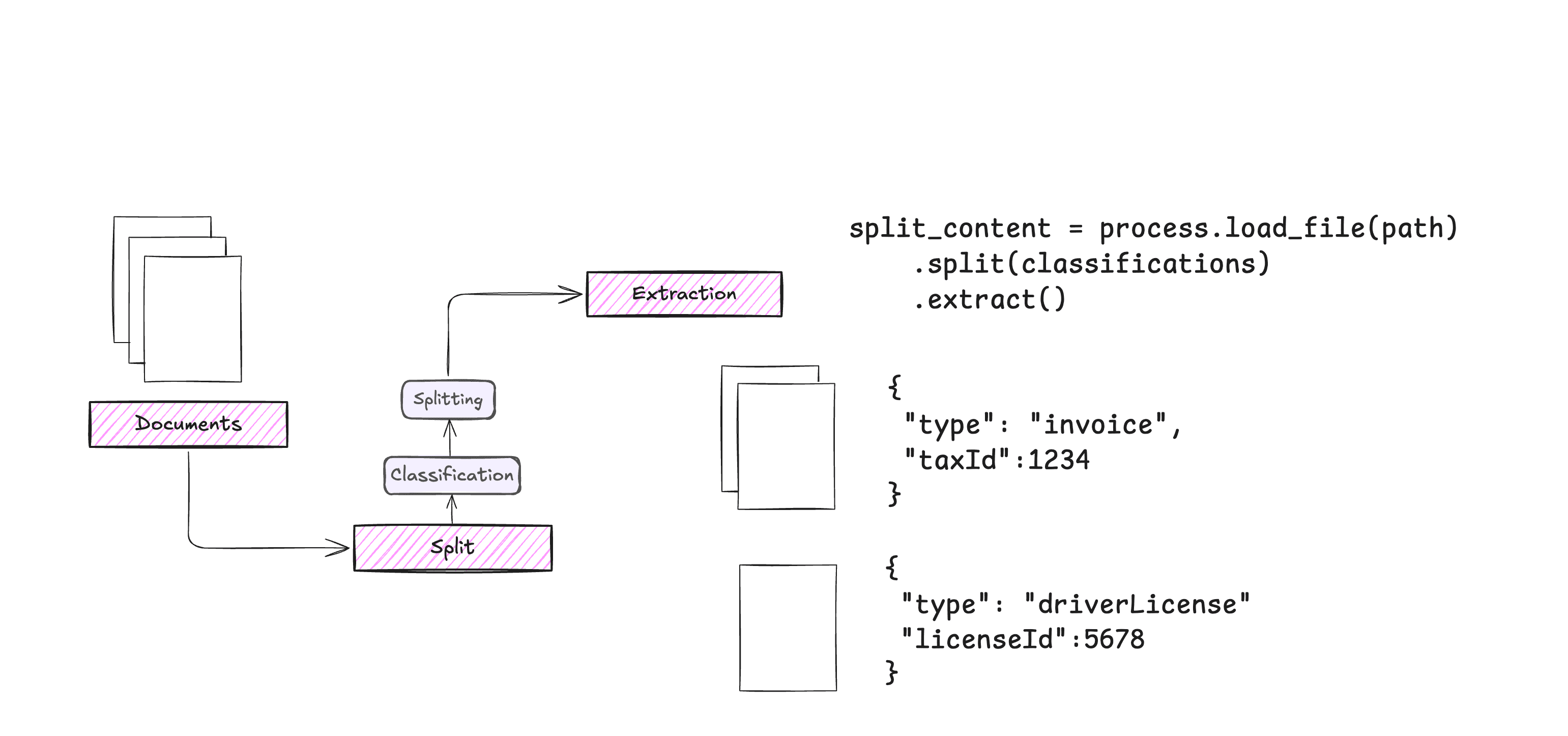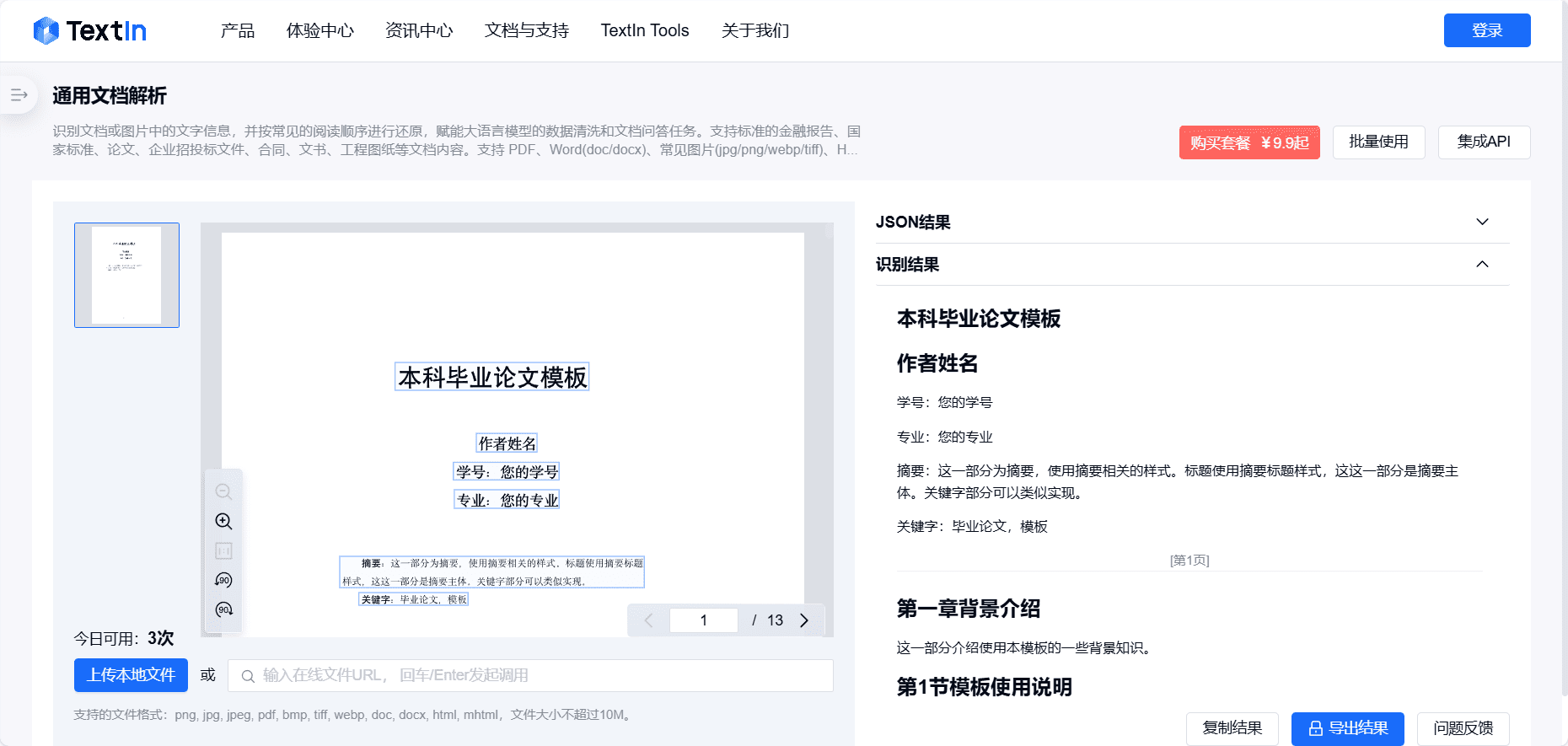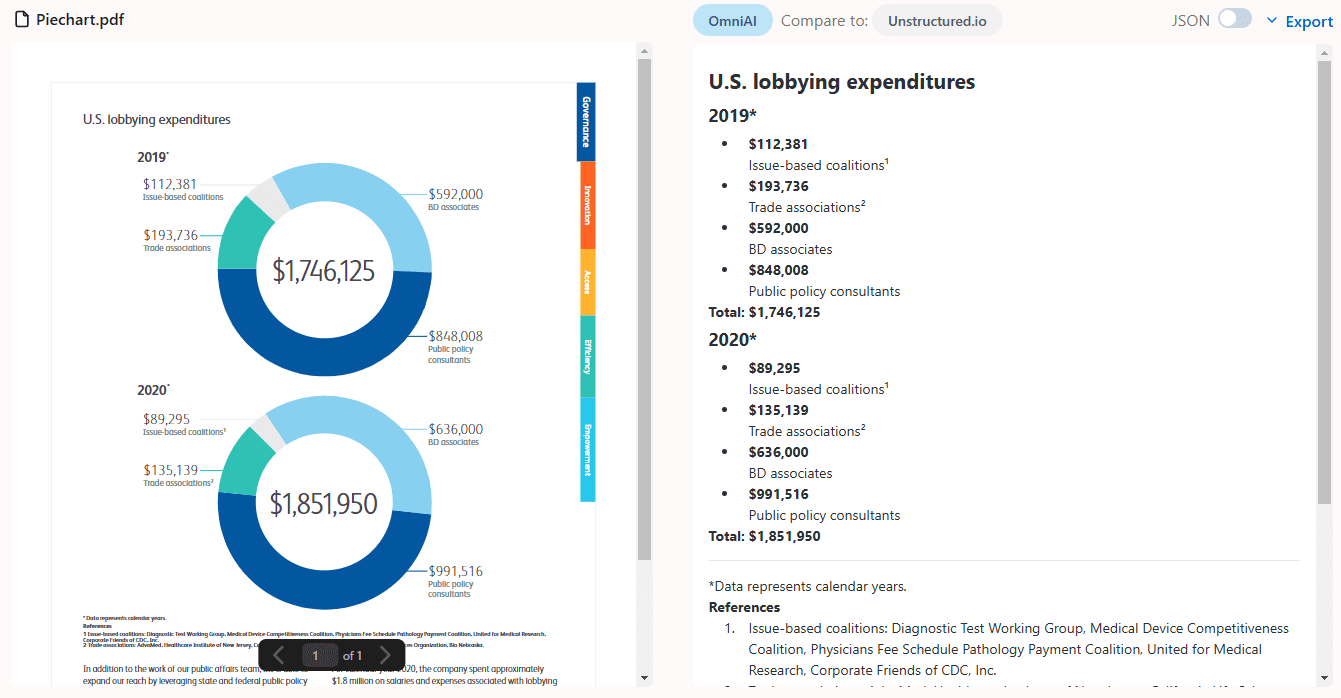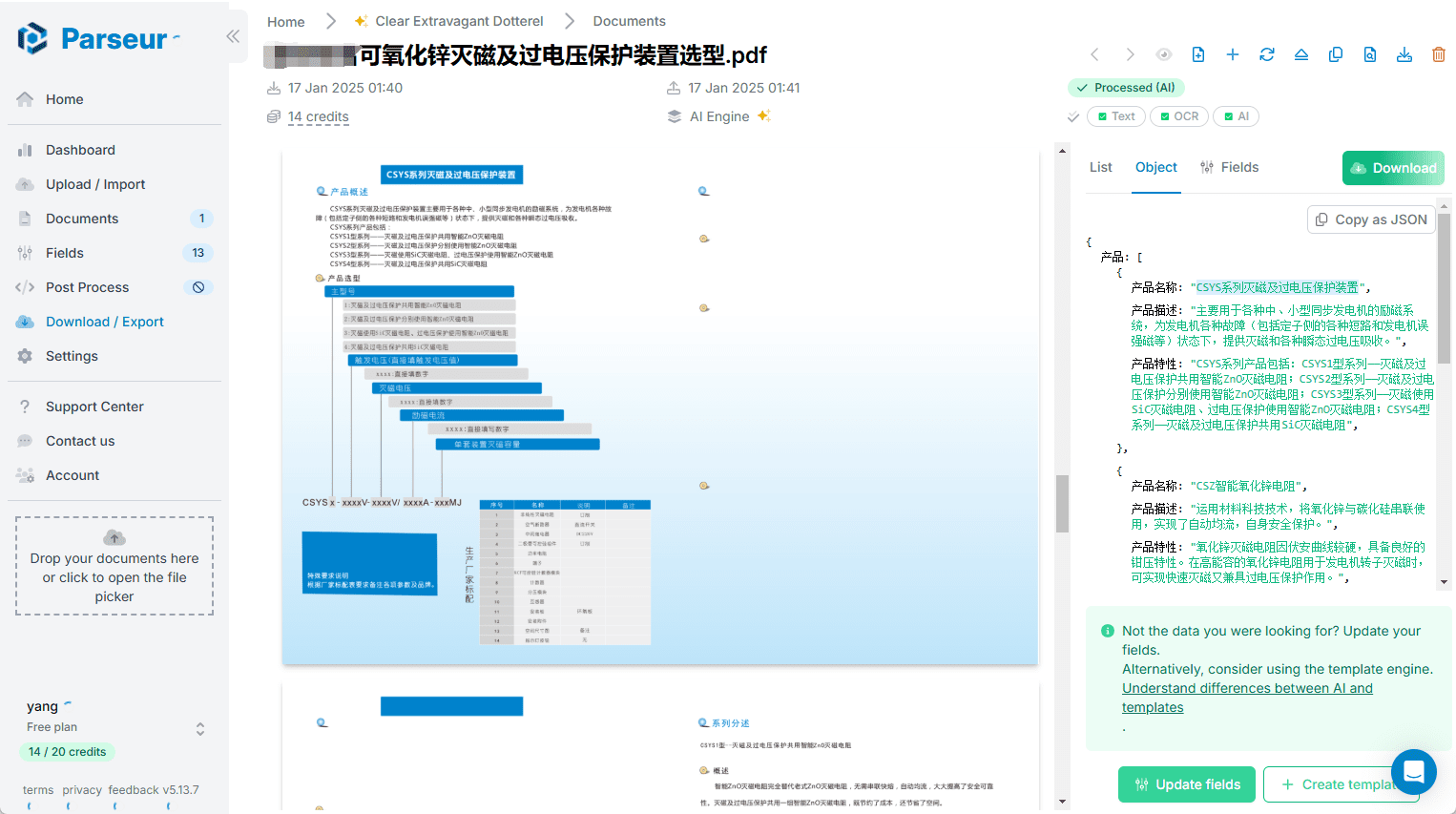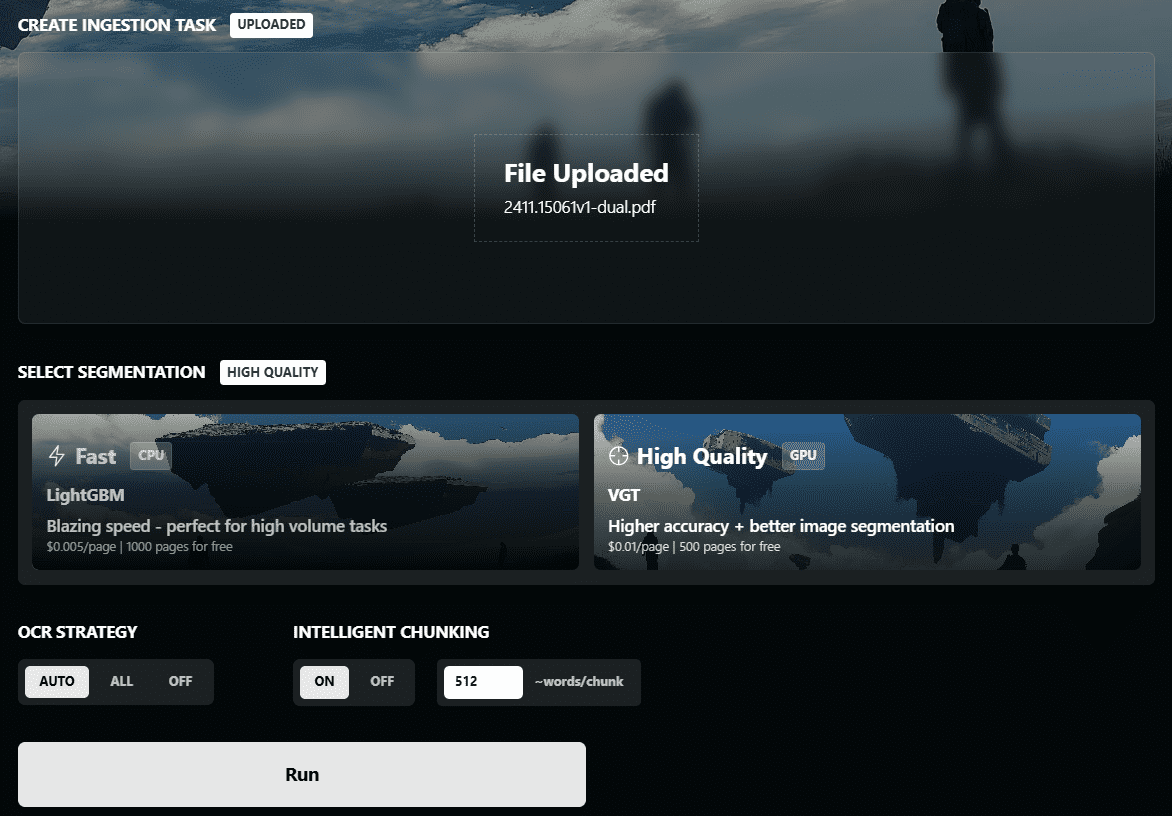
Chunkr: ein All-in-One-Dienst, der visuelle Modelle für die Aufnahme von Dokumenten und intelligentes Chunking auf der Grundlage von Textabsatzhierarchien verwendet
Allgemeine Einführung Chunkr ist eine selbst gehostete API zur Konvertierung von PDF-, PPTX-, DOCX- und Excel-Dateien in Daten, die für die Verwendung in RAG (Retrieval Augmented Generation) und LLM (Large Language Modelling) geeignet sind. Das Projekt wurde von Lumina entwickelt...