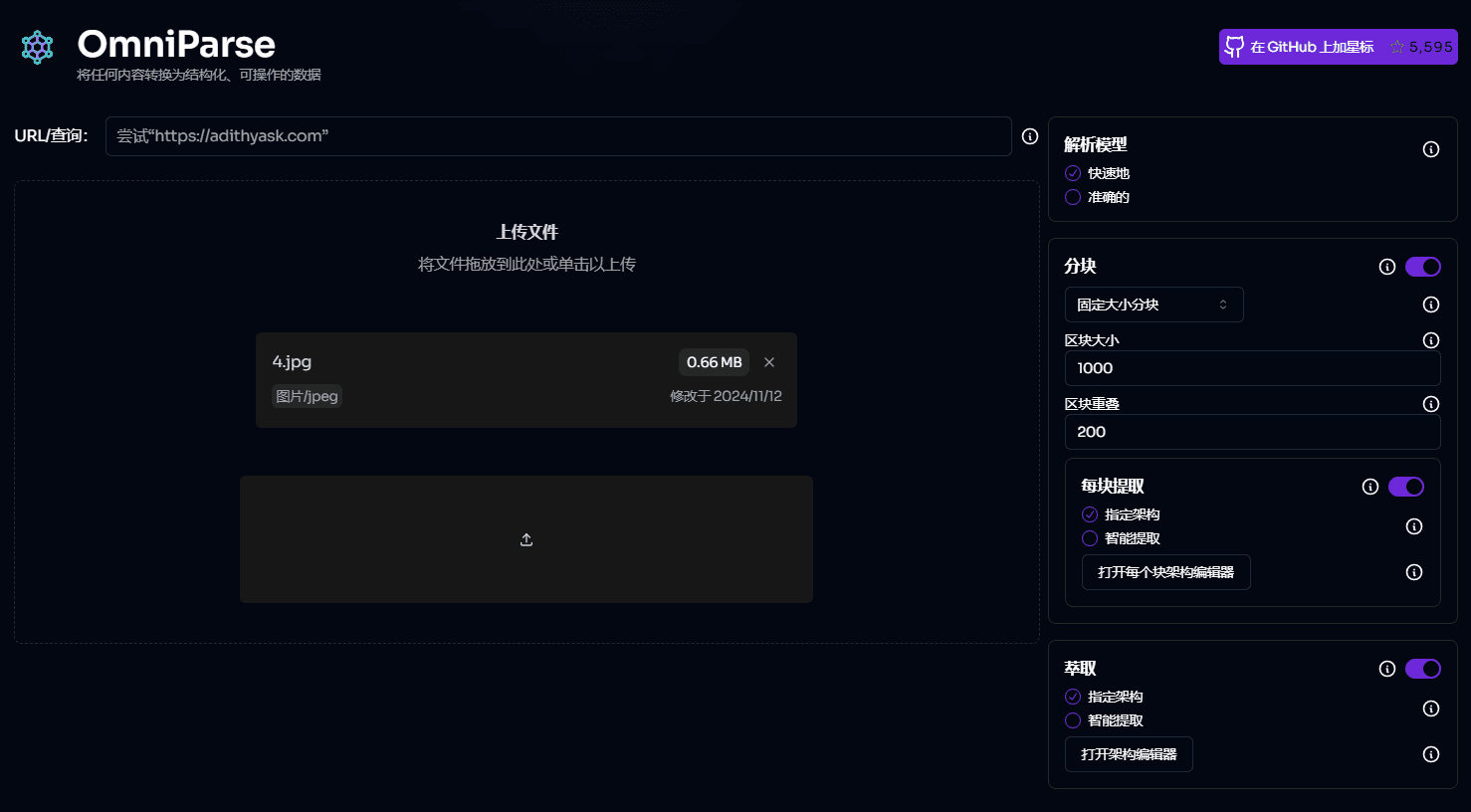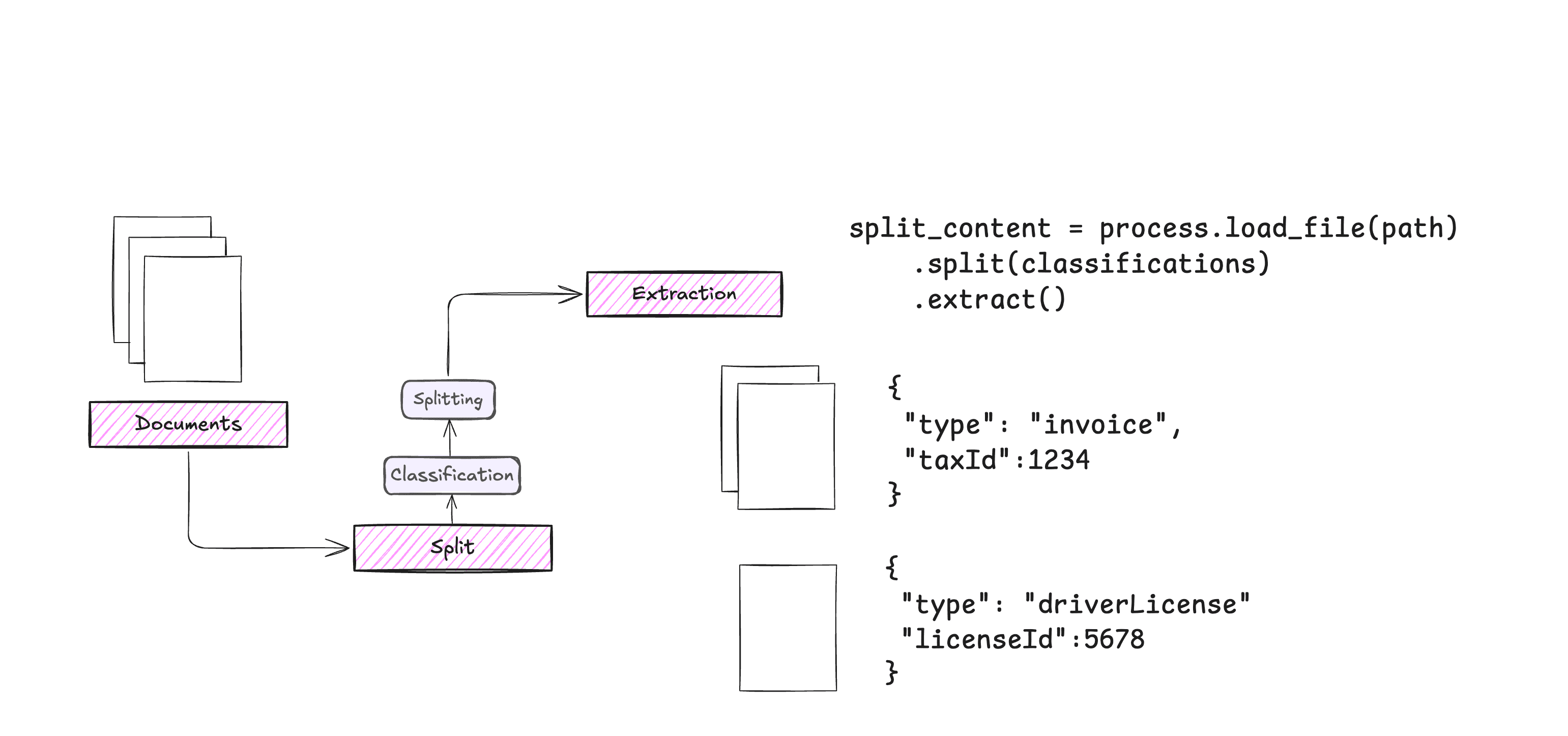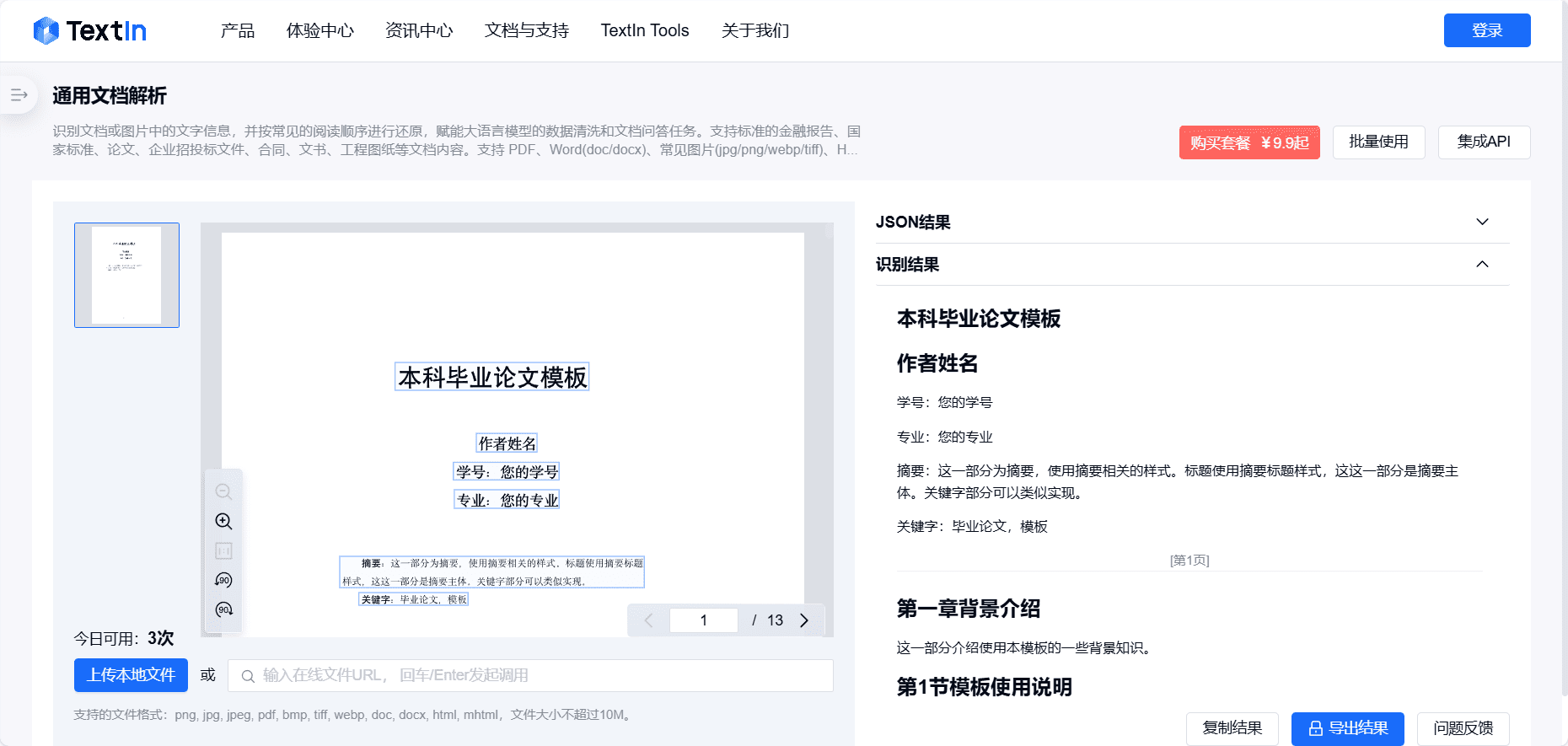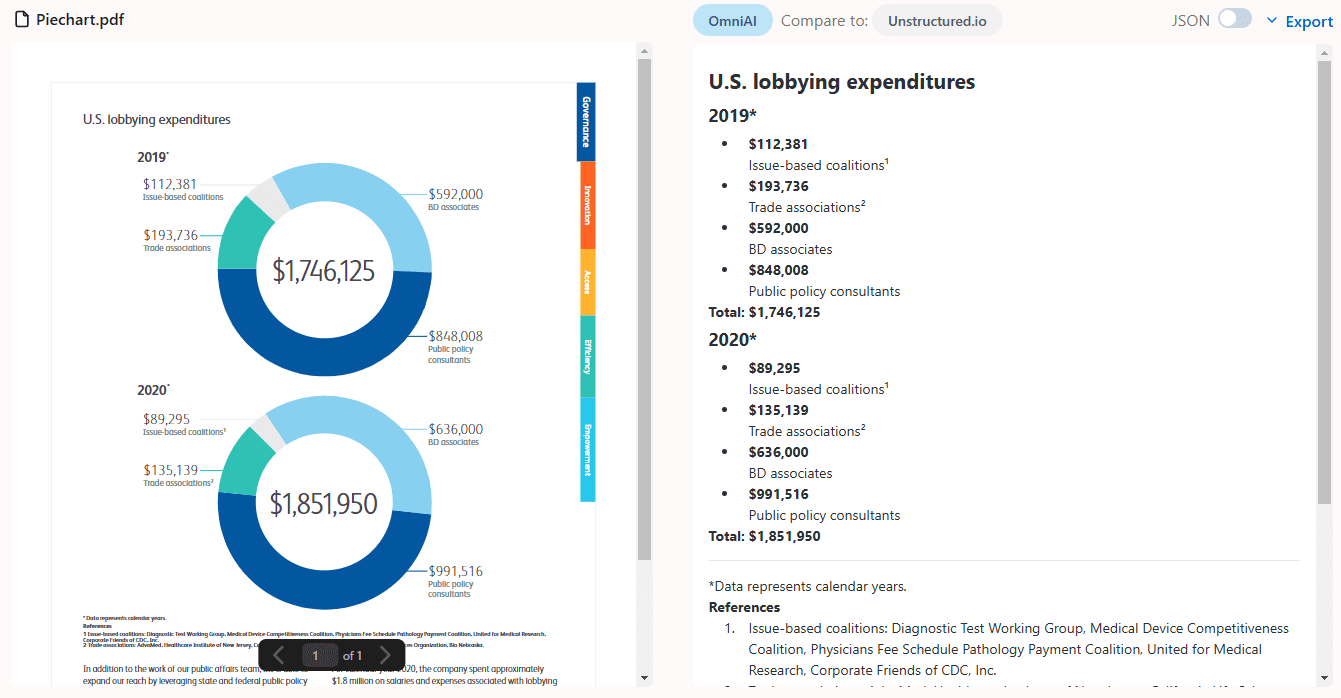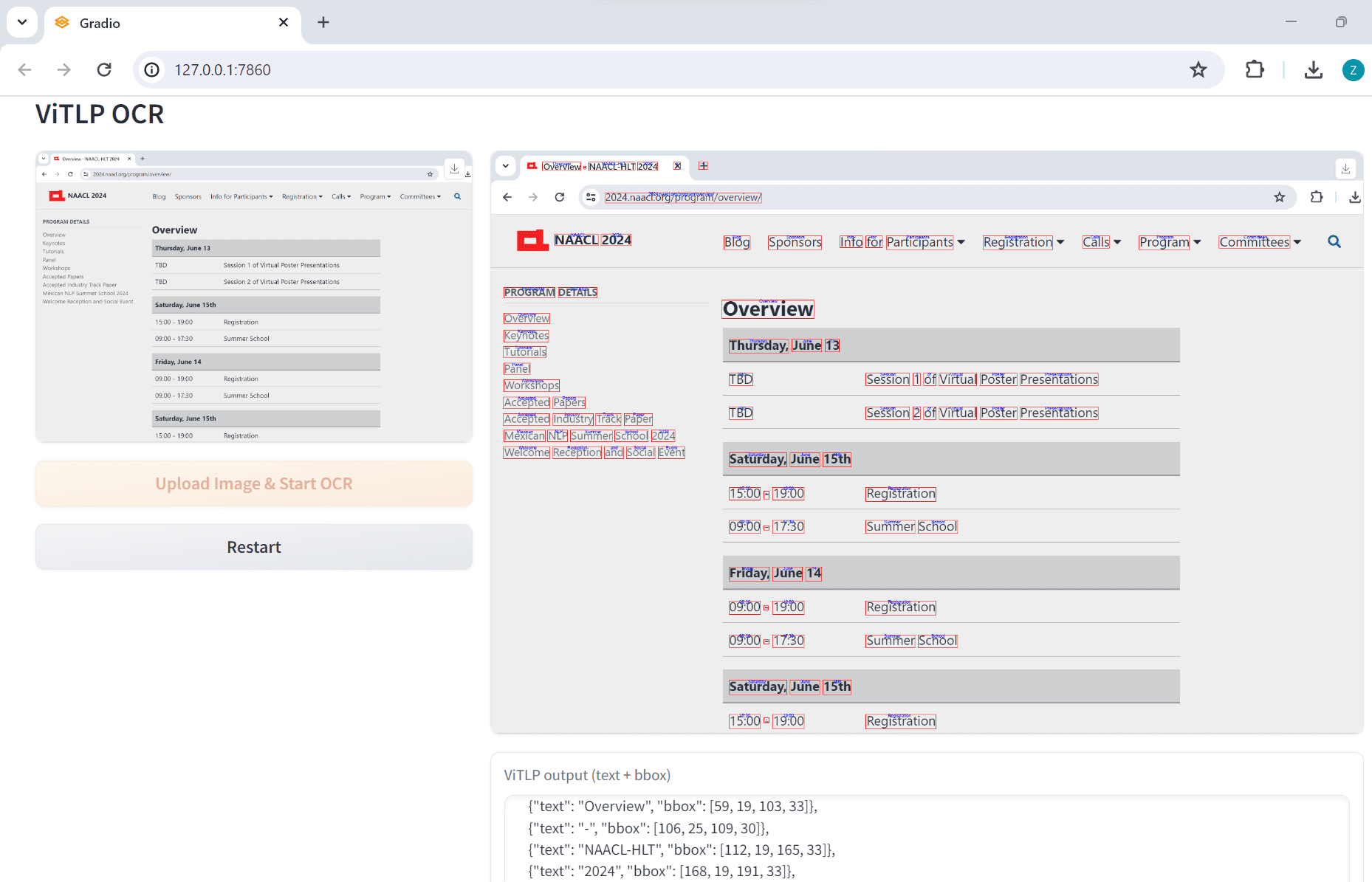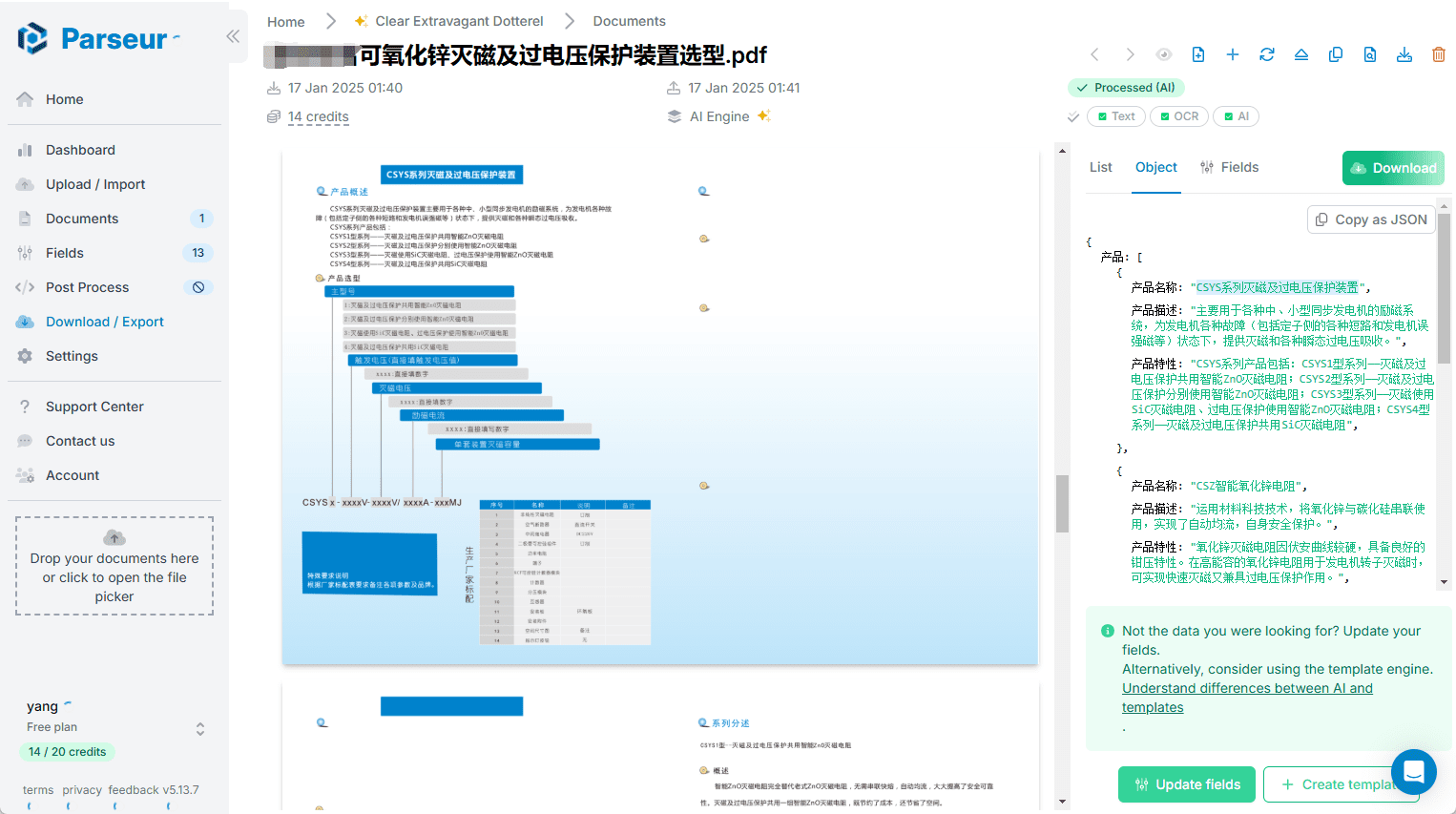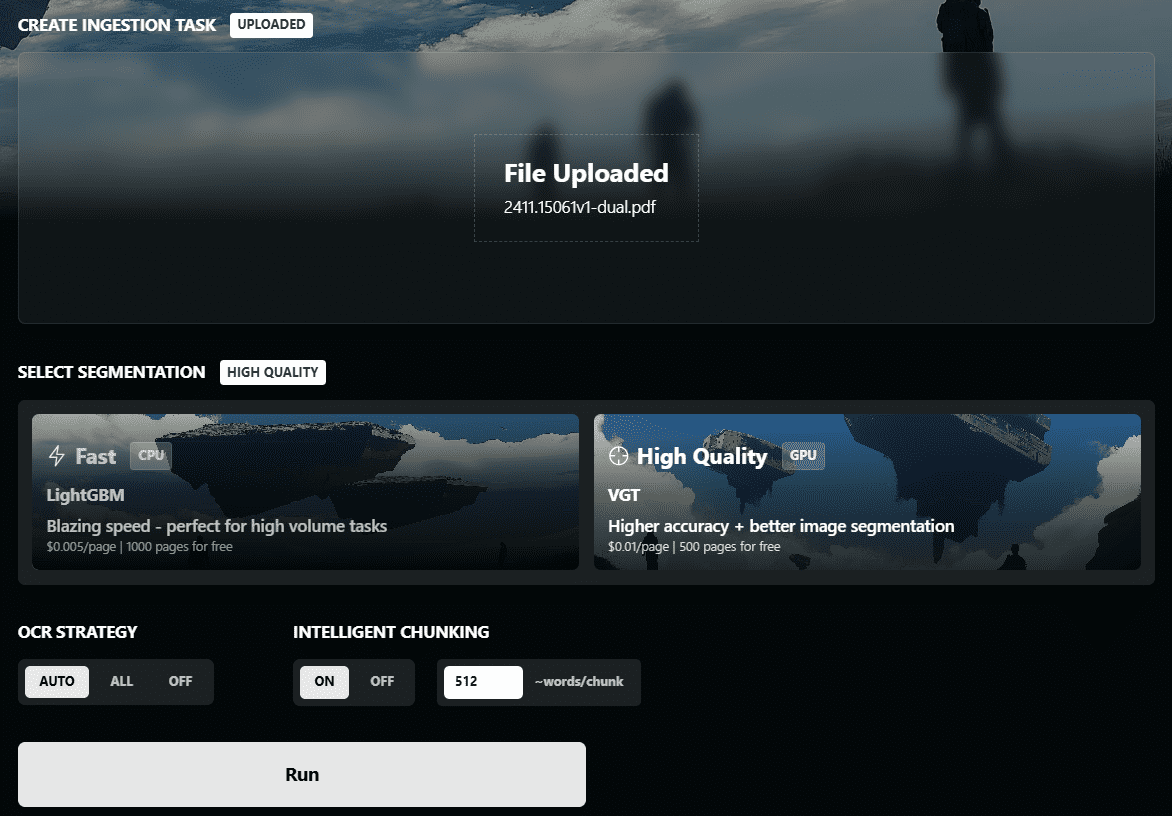
Chunkr: um serviço completo que usa modelos visuais para a ingestão de documentos e a divisão inteligente em blocos com base na hierarquia de parágrafos do texto
综合介绍 Chunkr 是一个自托管的 API,专门用于将 PDF、PPTX、DOCX 和 Excel 文件转换为适合 RAG(检索增强生成)和 LLM(大语言模型)使用的数据。该项目由 Lumina...