CodeWeaver: Genera automáticamente documentos Markdown a partir de la estructura y el contenido del código.
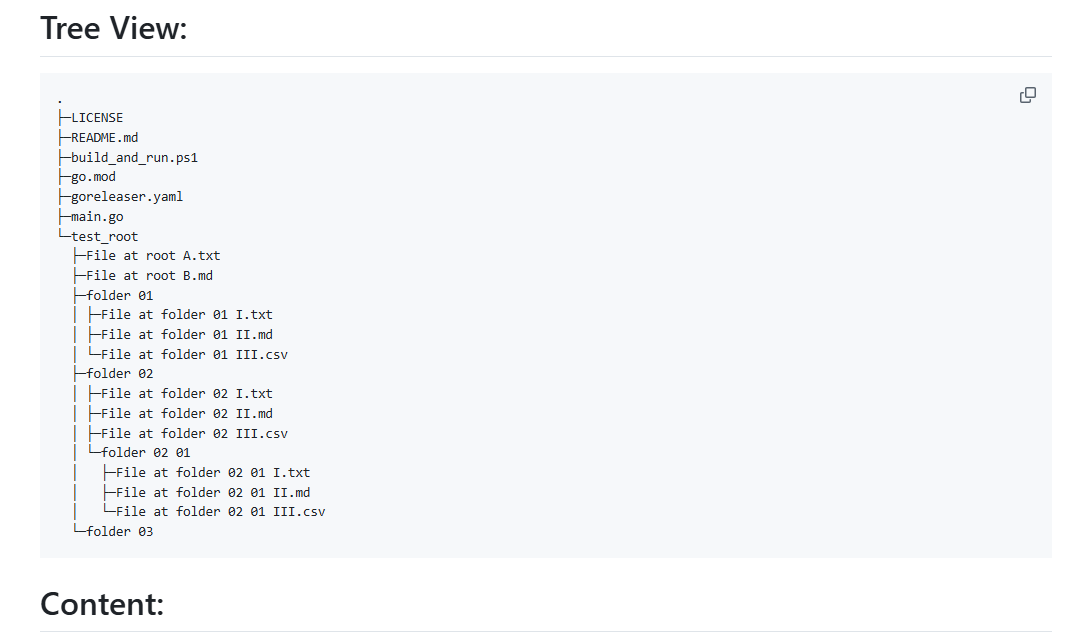
Introducción general CodeWeaver es una herramienta de línea de comandos diseñada para entretejer bibliotecas de código en documentos Markdown únicos y fáciles de navegar. Genera una representación estructurada de la jerarquía de archivos de un proyecto escaneando recursivamente los directorios e incrustando el contenido de cada archivo en bloques de código. Esta herramienta...