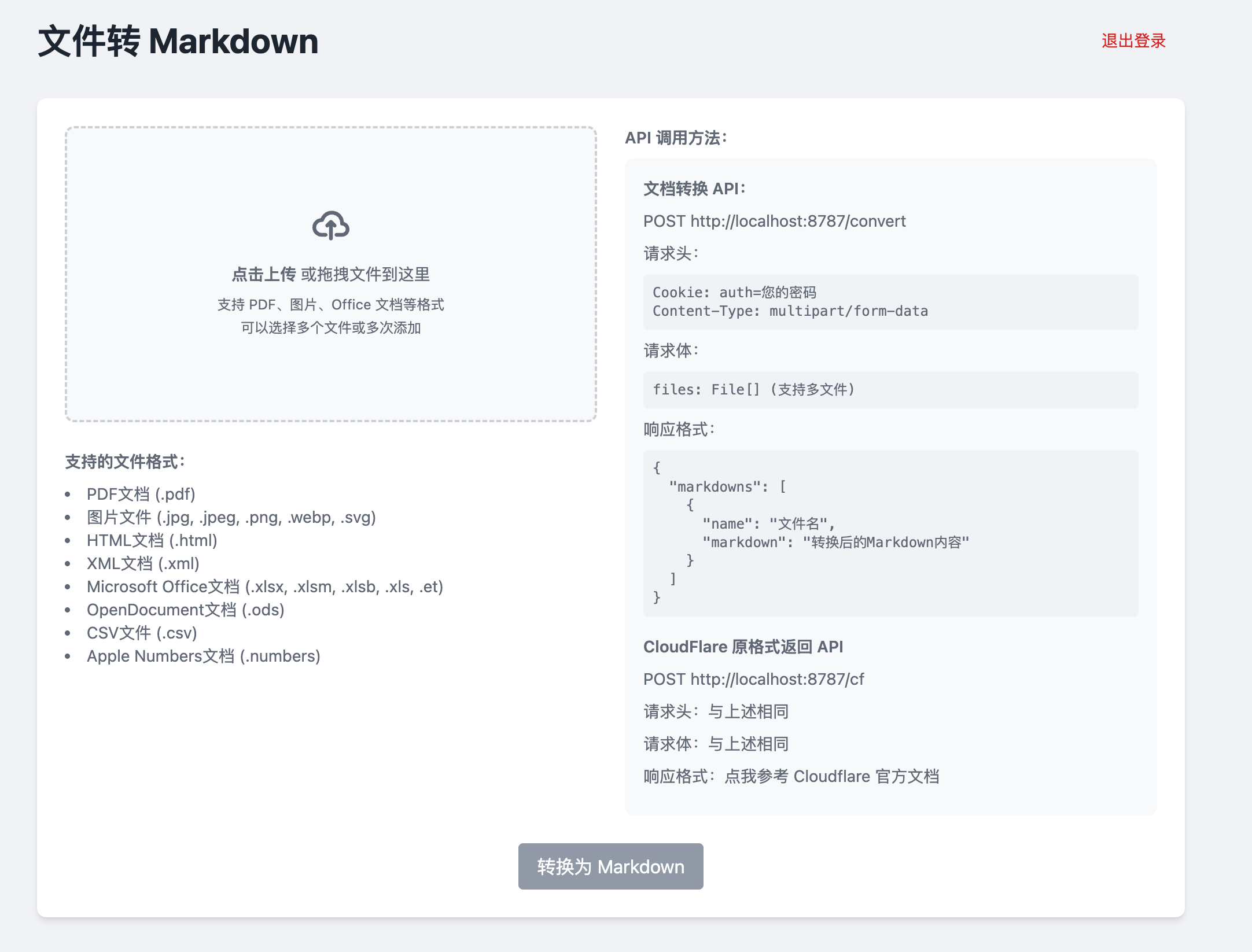
GPT-Crawler: rastreo automático de contenidos web para generar documentos de bases de conocimiento
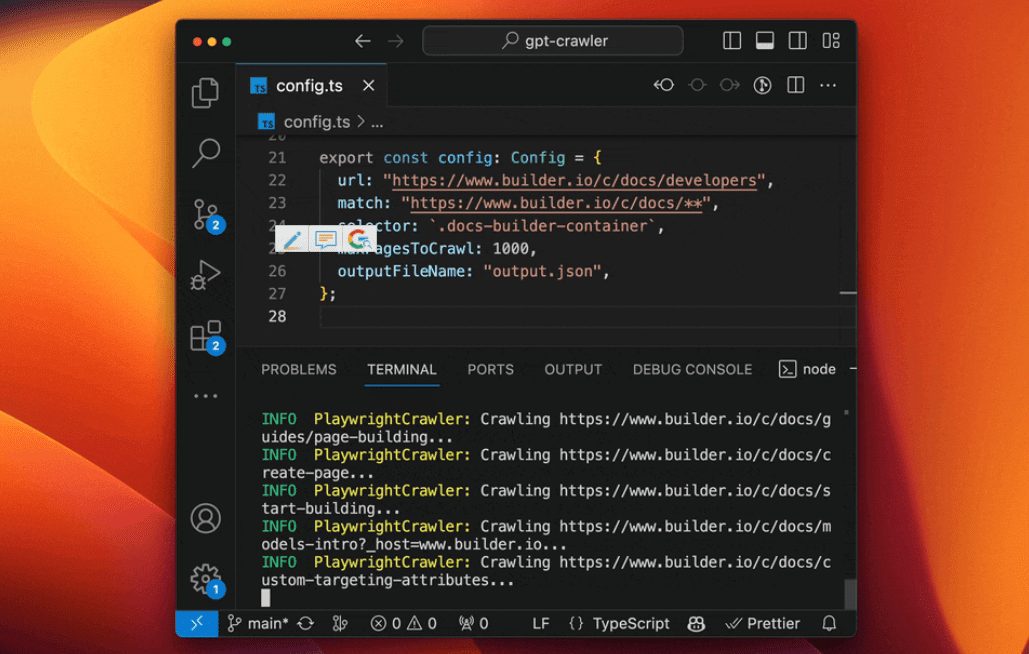
Introducción general GPT-Crawler es una herramienta de código abierto desarrollada por el equipo BuilderIO y alojada en GitHub. Rastrea el contenido de las páginas introduciendo una o varias URL de sitios web, generando archivos de conocimiento estructurado (output.jso...