Ollama OCR: Extracción de texto de imágenes mediante modelos visuales en Ollama
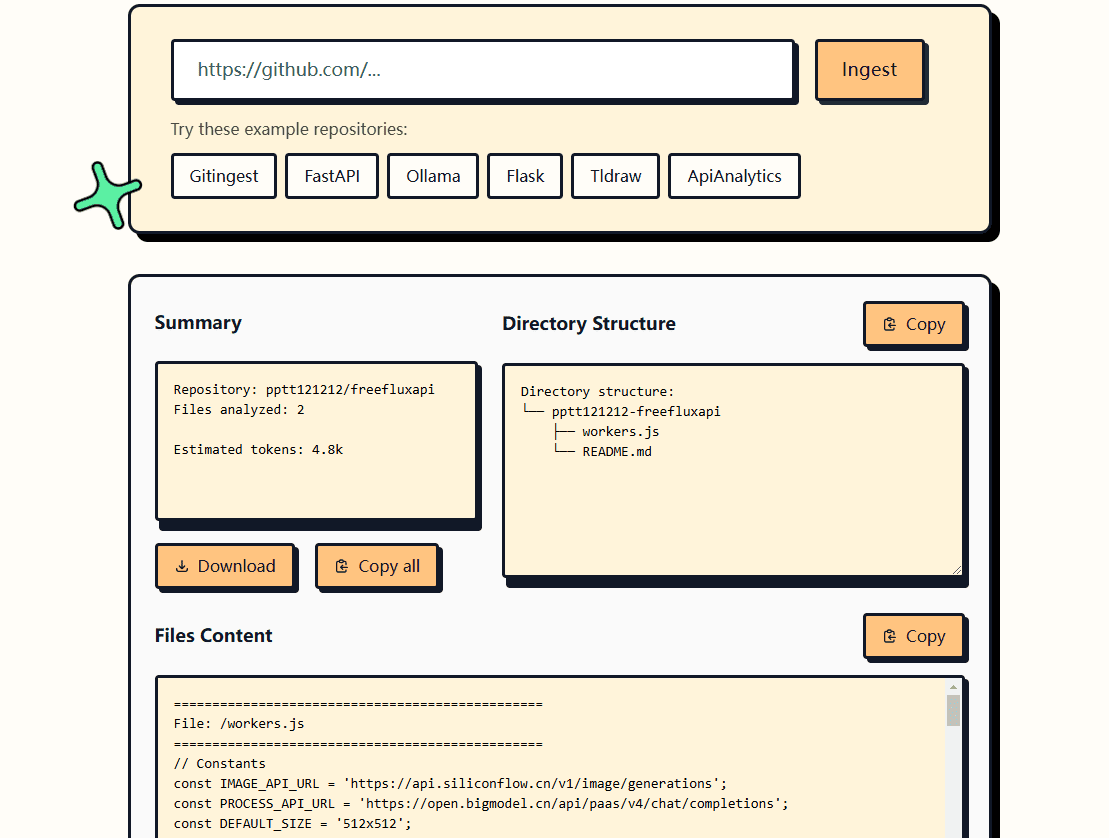
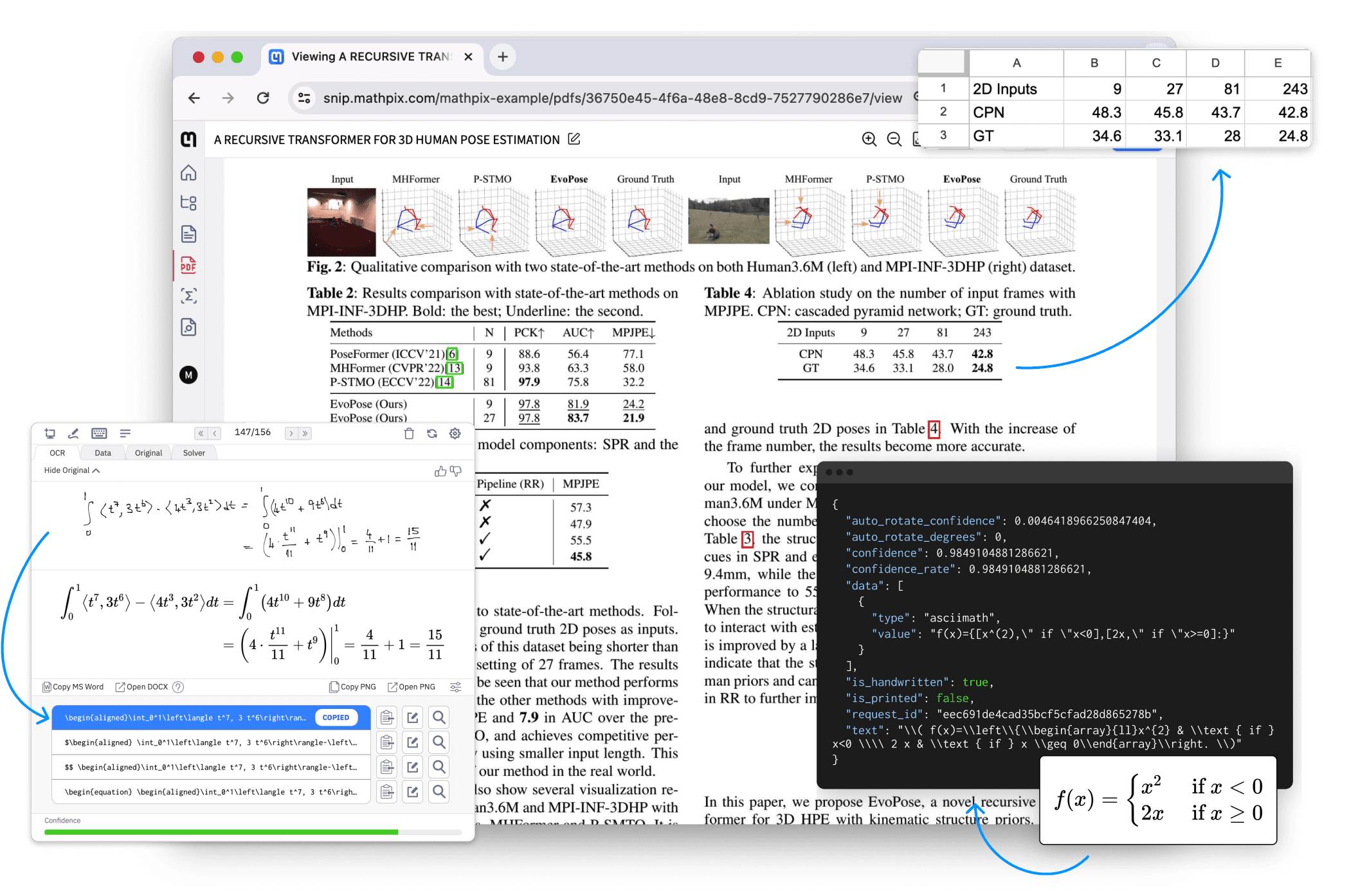
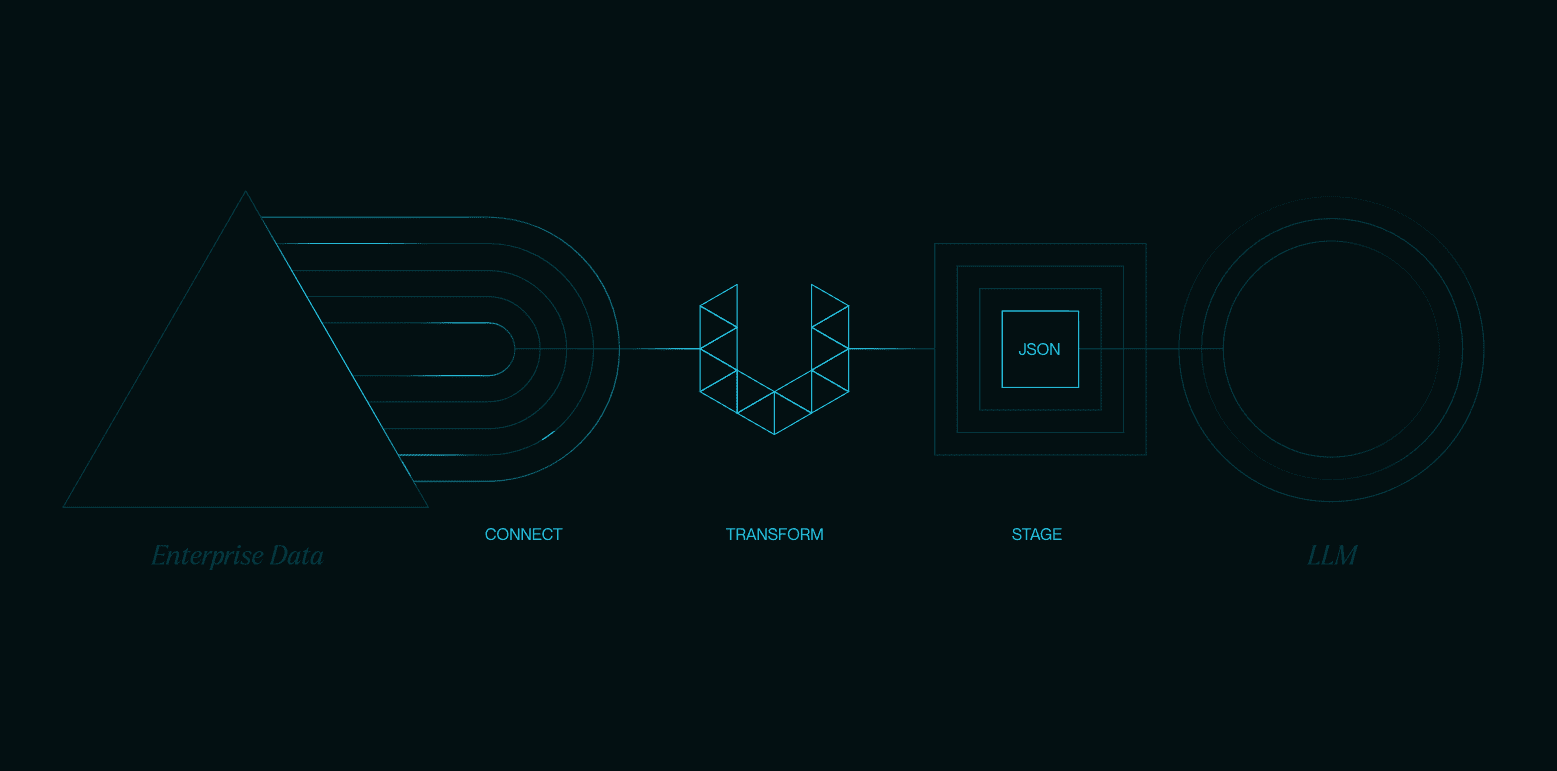
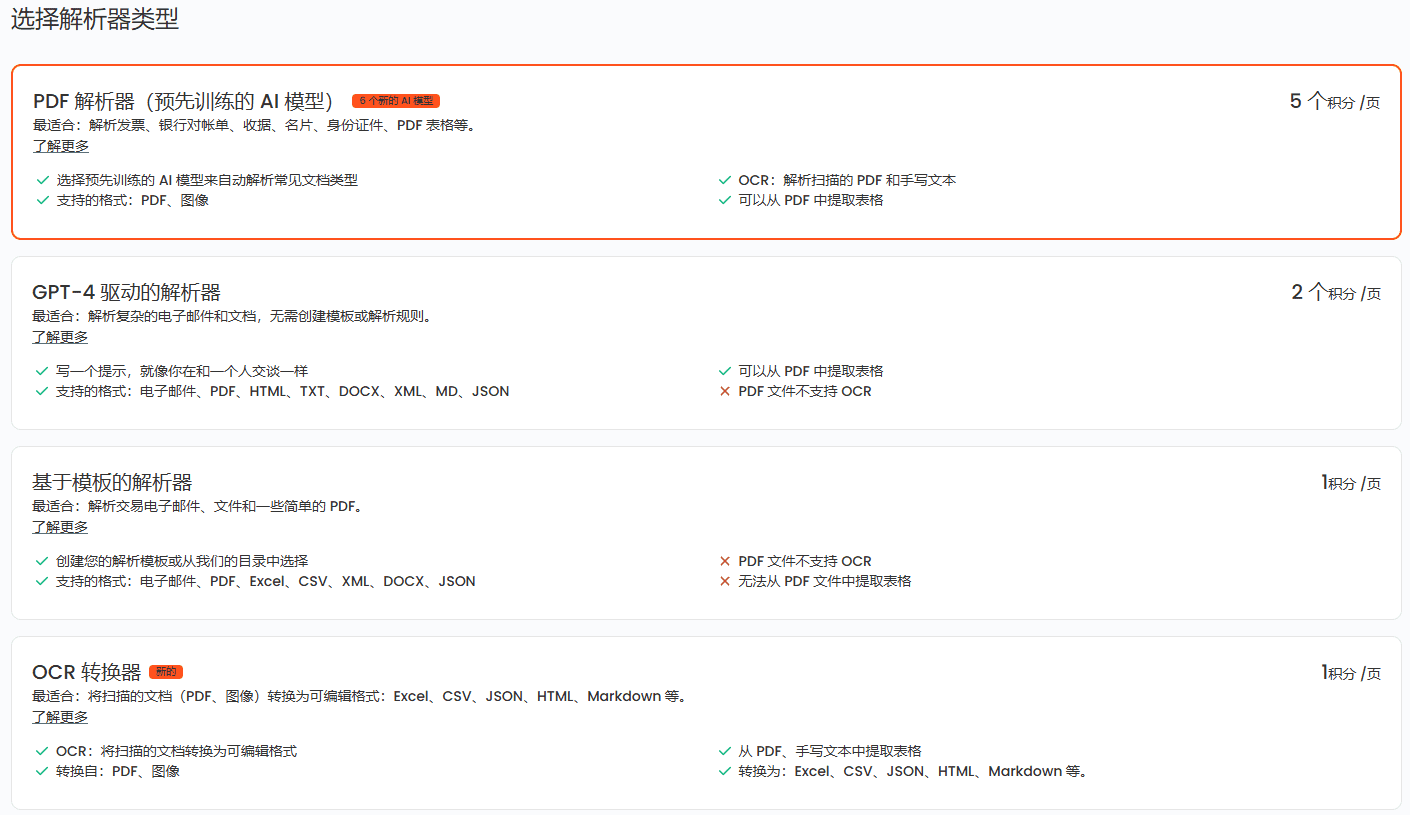
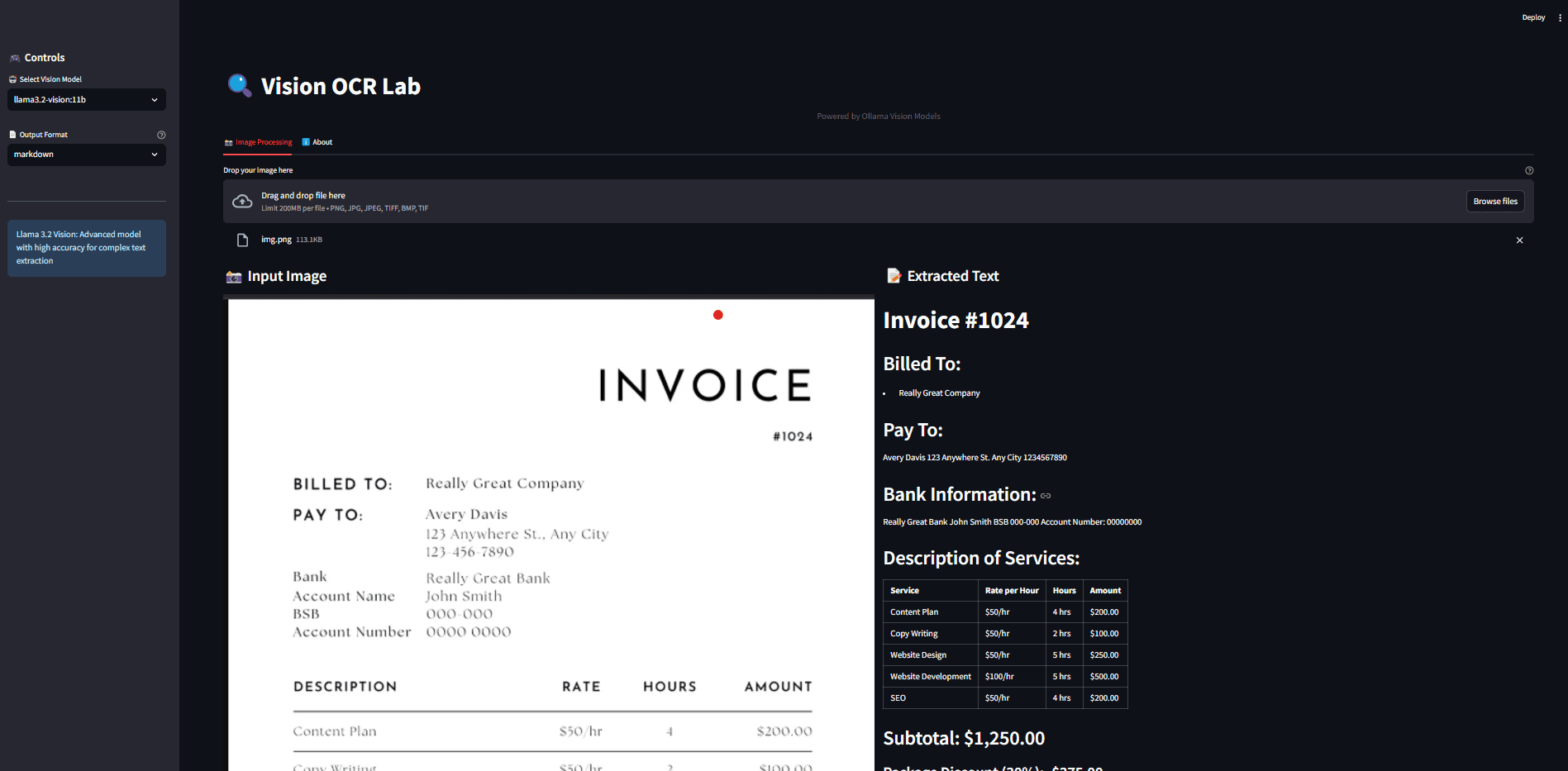
Introducción general Ollama OCR es un potente kit de herramientas de reconocimiento óptico de caracteres (OCR) que utiliza el modelo de lenguaje visual de última generación proporcionado por la plataforma Ollama para extraer texto de imágenes. El proyecto está disponible como paquete Python y proporciona una interfaz Strea...