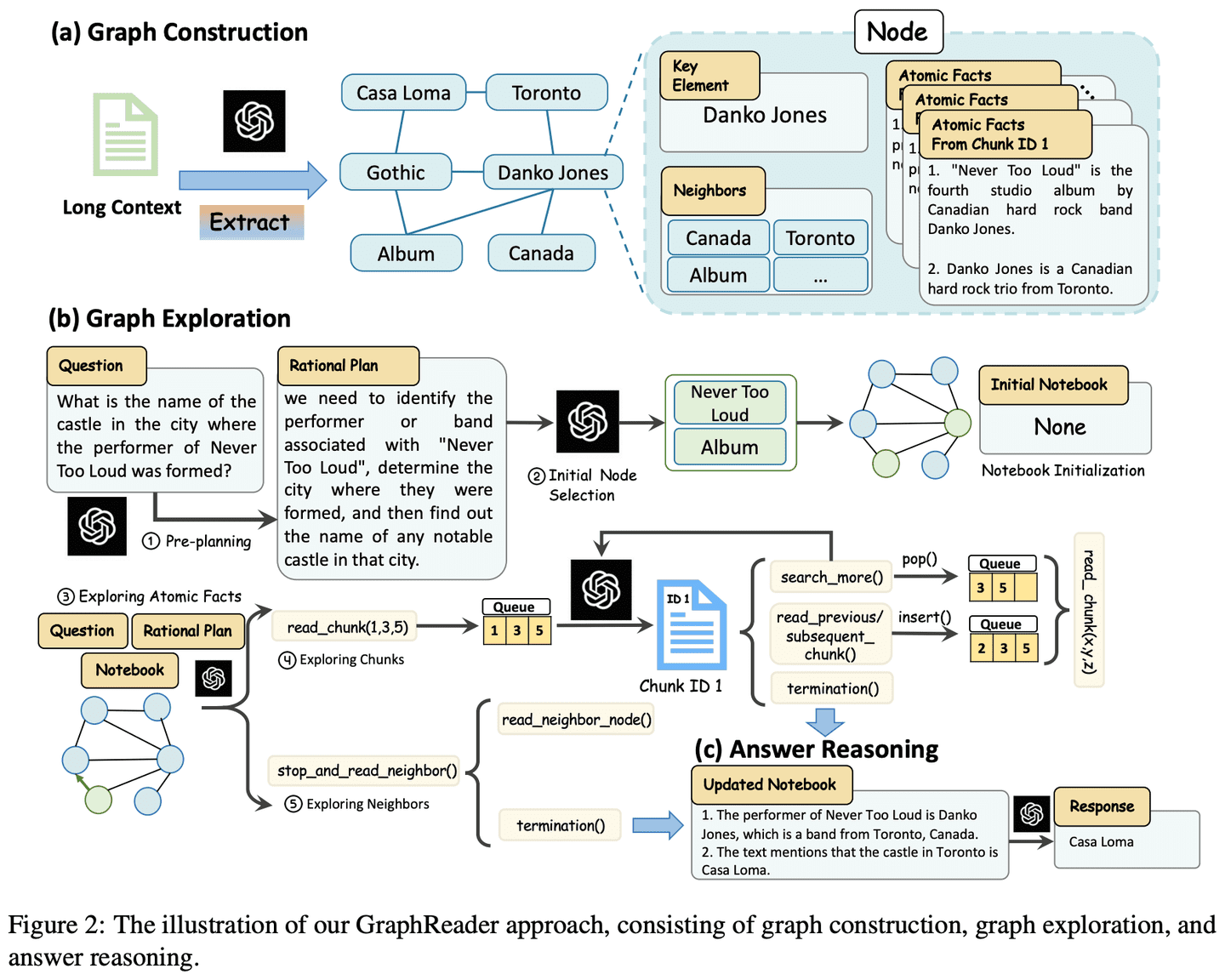
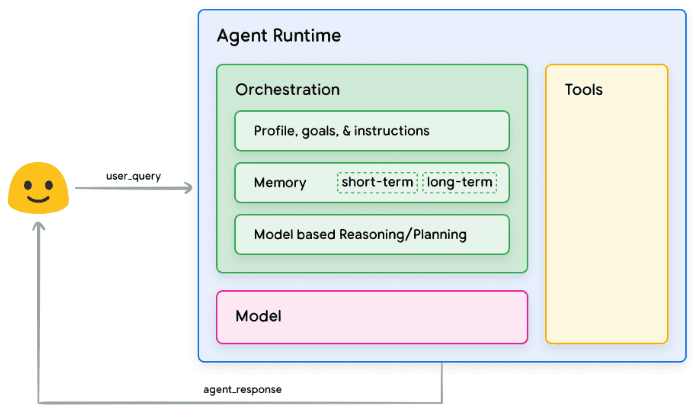
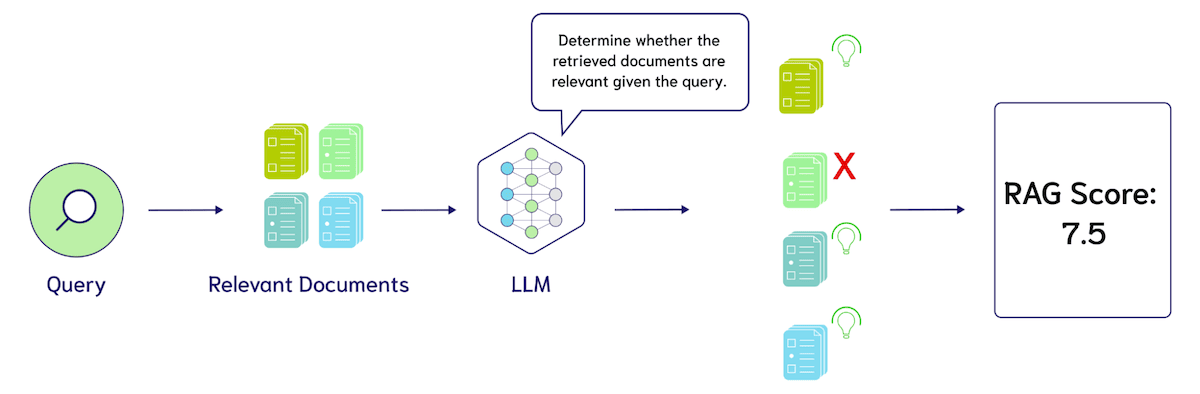
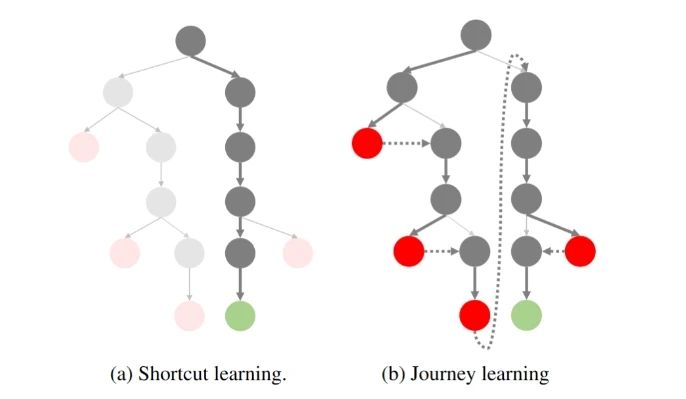
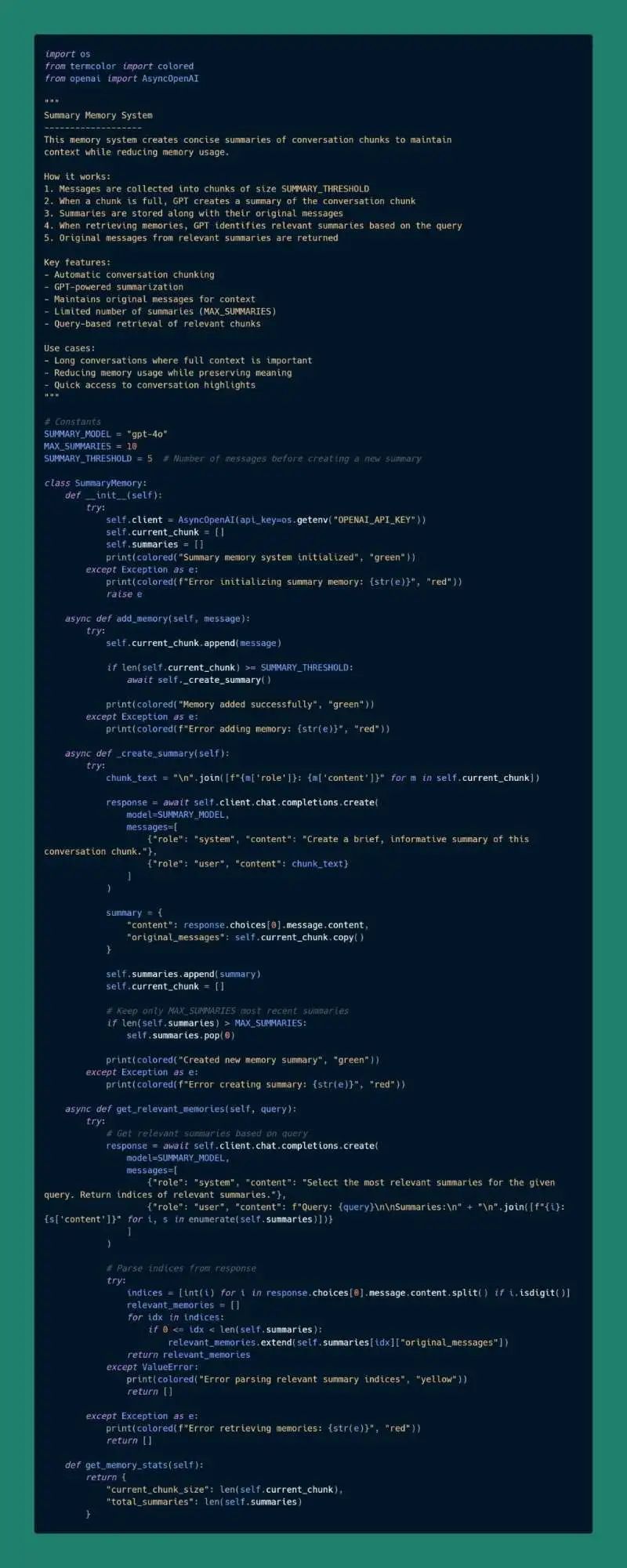
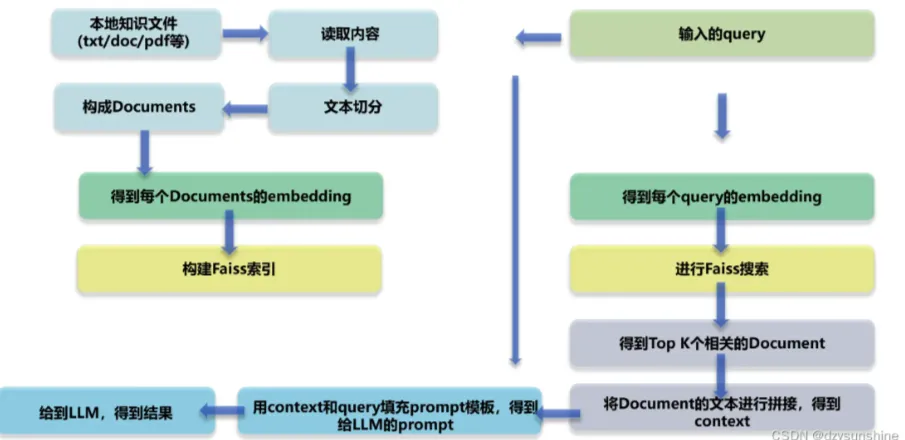
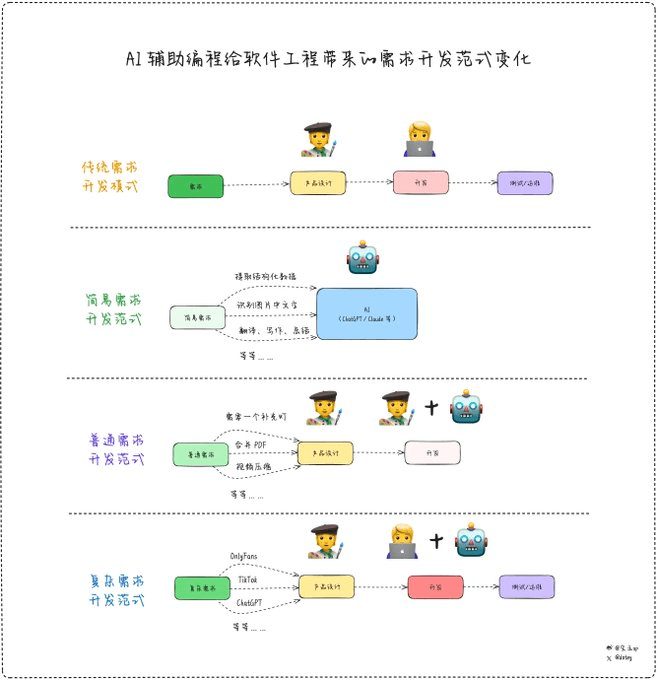
Ao criar aplicativos de modelo de linguagem ampla (LLM), os sistemas de memória são uma das principais tecnologias para aprimorar o gerenciamento do contexto do diálogo, o armazenamento de informações de longo prazo e a compreensão semântica. Um sistema de memória eficiente pode ajudar o modelo a manter a consistência em diálogos longos, extrair informações importantes e até mesmo ter a capacidade de recuperar o histórico do diálogo...







![Agent AI: 探索多模态交互的前沿世界[李飞飞-经典必读]](https://oss.sharenet.ai/wp-content/uploads/2025/01/6dbf9ac2da09ee1.png)