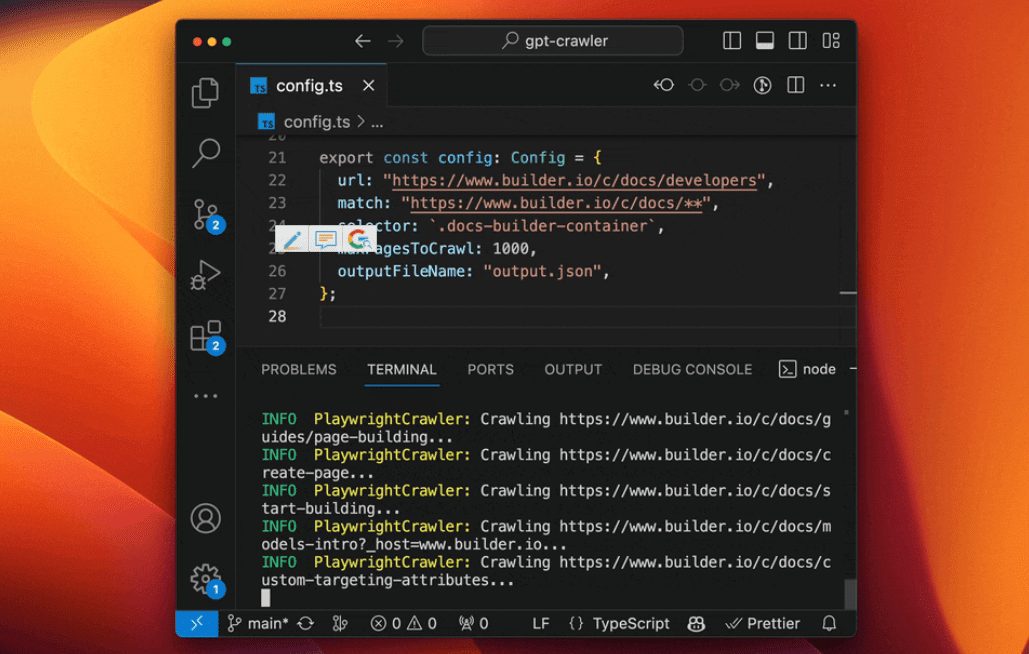
GPT-Crawler: ウェブサイトコンテンツを自動的にクロールして知識ベースドキュメントを生成综合介绍 GPT-Crawler 是由 BuilderIO 团队开发的一个开源工具,托管在 GitHub 上。它通过输入一个或多个网站 URL,爬取页面内容,生成结构化的知识文件(output.jso...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1ヶ月前01.5K
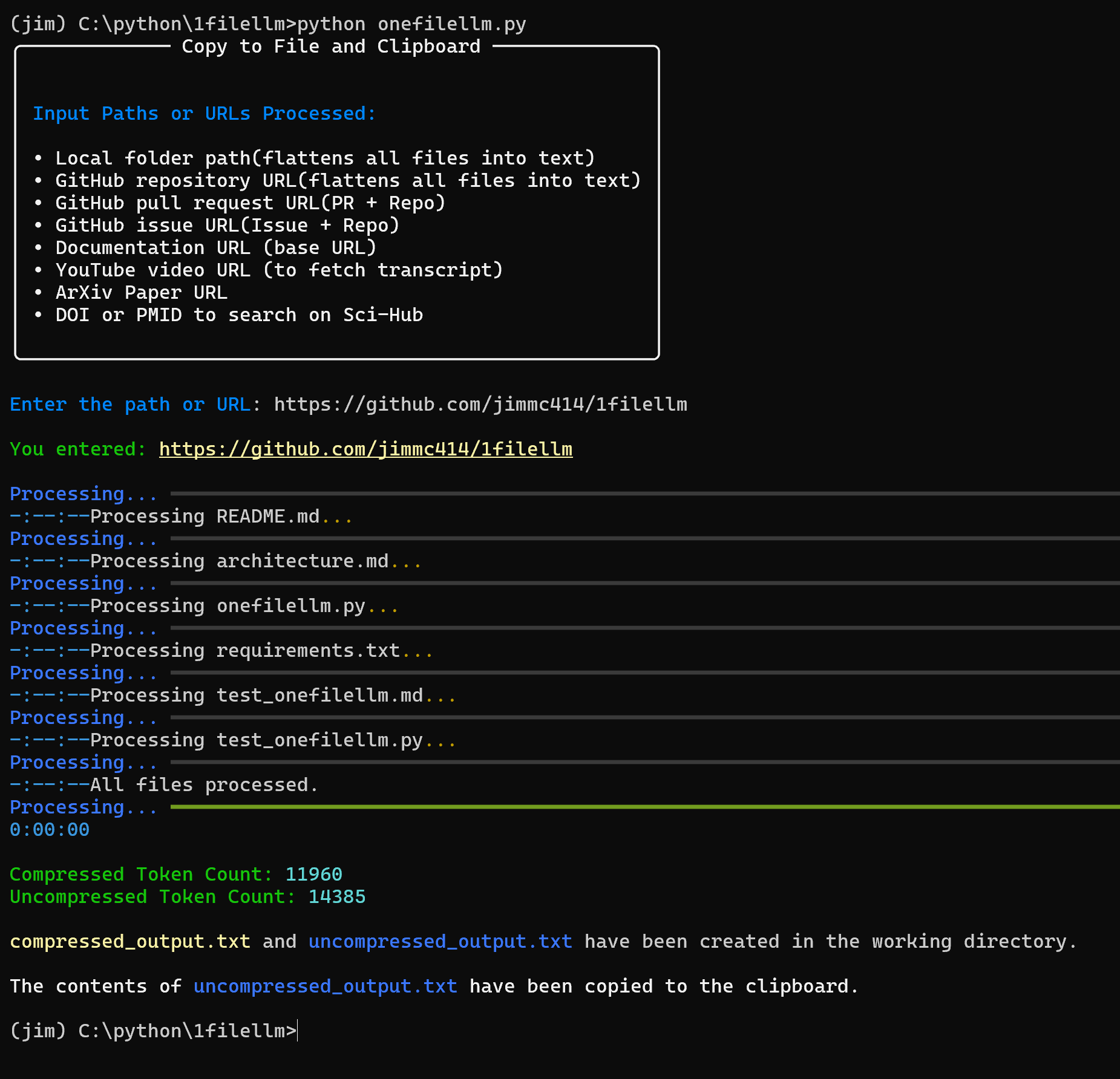
OneFileLLM: 複数のデータソースを単一のテキストファイルに統合综合介绍 OneFileLLM 是一个开源命令行工具,旨在将多种数据源整合成单一文本文件,方便输入大语言模型(LLM)。它支持处理 GitHub 仓库、ArXiv 论文、YouTube 视频转录、网页...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング3ヶ月前0458
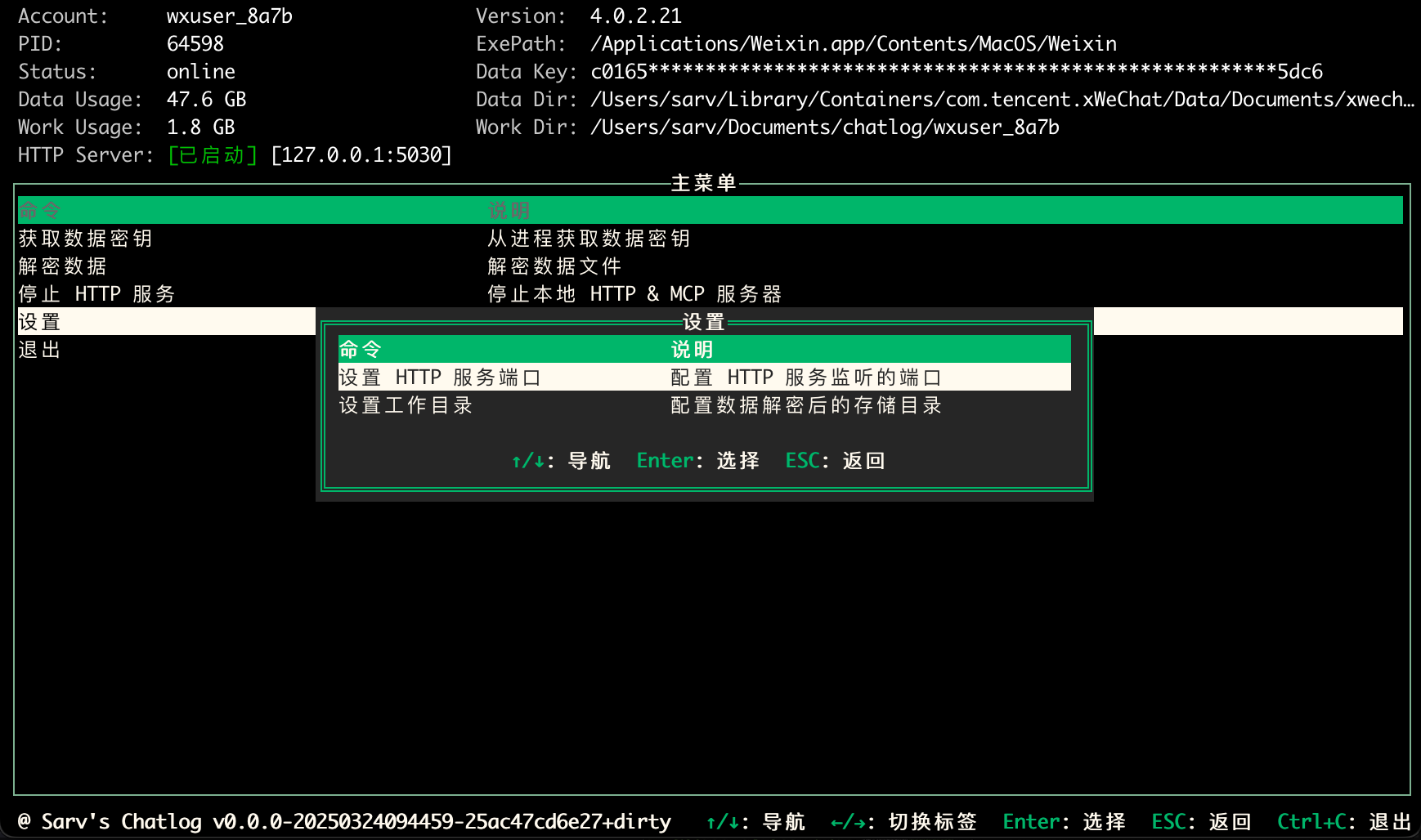
Chatlog: WeChatのチャットログを抽出・照会するオープンソースツール一般的な紹介 チャットログはWeChatのローカルデータベースからチャットログを抽出し、照会することに特化したオープンソースツールです。WeChatバージョン3.xと4.0をサポートし、WindowsとmacOSの両システムをカバーしています。ユーザーは、コマンドライン、ターミナルインターフェース、またはH...最新のAIツール# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング3ヶ月前0636
VOP: 複雑な図や数式を抽出するOCRツール综合介绍 Versatile OCR Program 是一个开源的光学字符识别(OCR)工具,专门为处理复杂的学术和教育文档设计。它能从PDF、图像等文件中提取文本、表格、数学公式、图表和示意图,并生...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング3ヶ月前0563
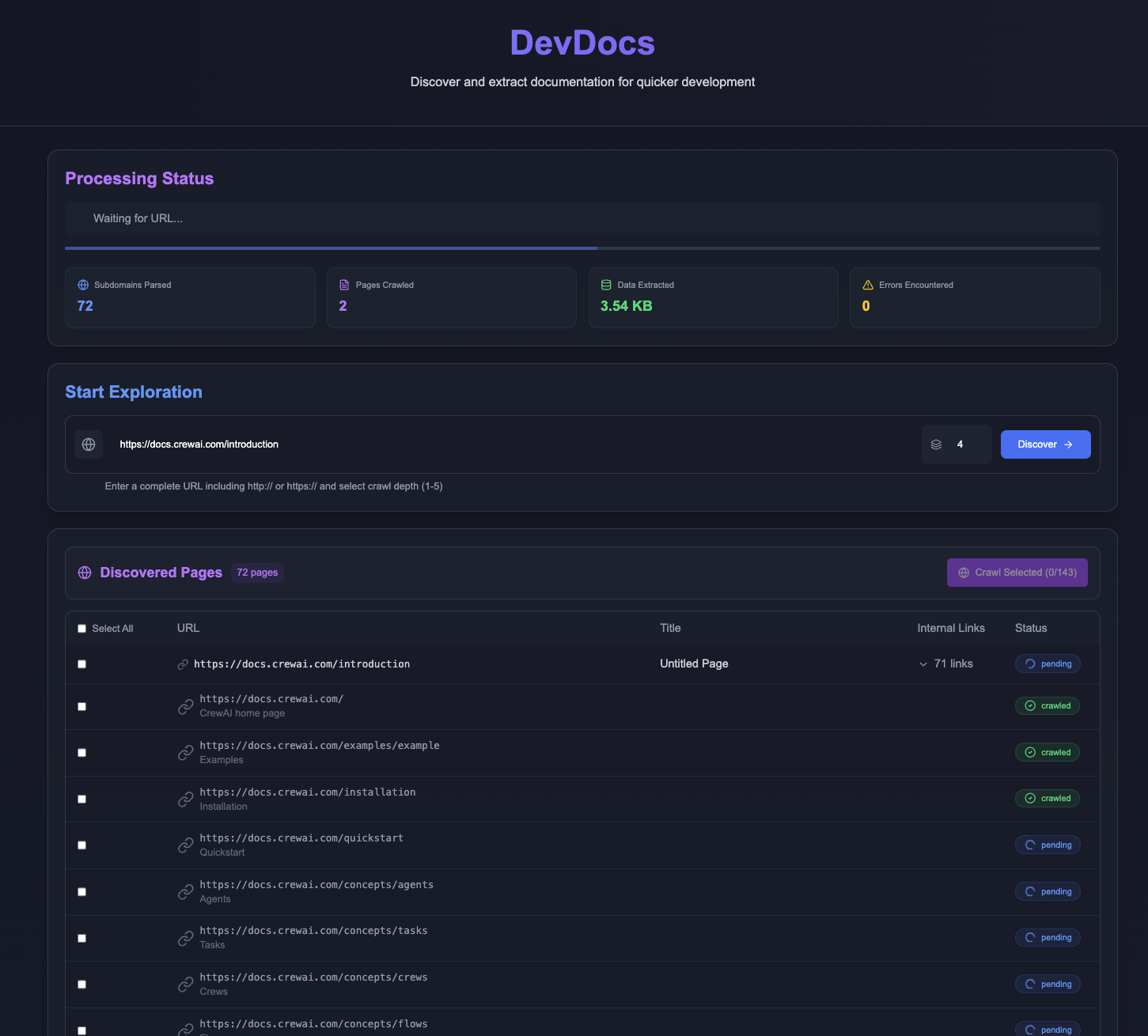
DevDocs:技術文書を素早くクロールして整理するMCPサービス概要 DevDocsは、CyberAGIチームによって開発され、GitHubでホストされている完全に無料のオープンソースツールです。プログラマーやソフトウェア開発者のために設計されたこのツールは、技術文書のURLから始まり、関連するページを自動的にクロールし、簡潔なMa...最新のAIツール# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング3ヶ月前0578
PDFコンテンツを自動的に解析し、オープンソースサービスのテキストとテーブルを抽出します。综合介绍 它能自动分析PDF文档的布局,识别页面中的文字、标题、图片、表格、公式等元素,并判断它们的正确顺序。工具支持OCR功能,可以把扫描PDF转为可搜索文本。它基于Docker运行,提供两种模型...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング3ヶ月前0617
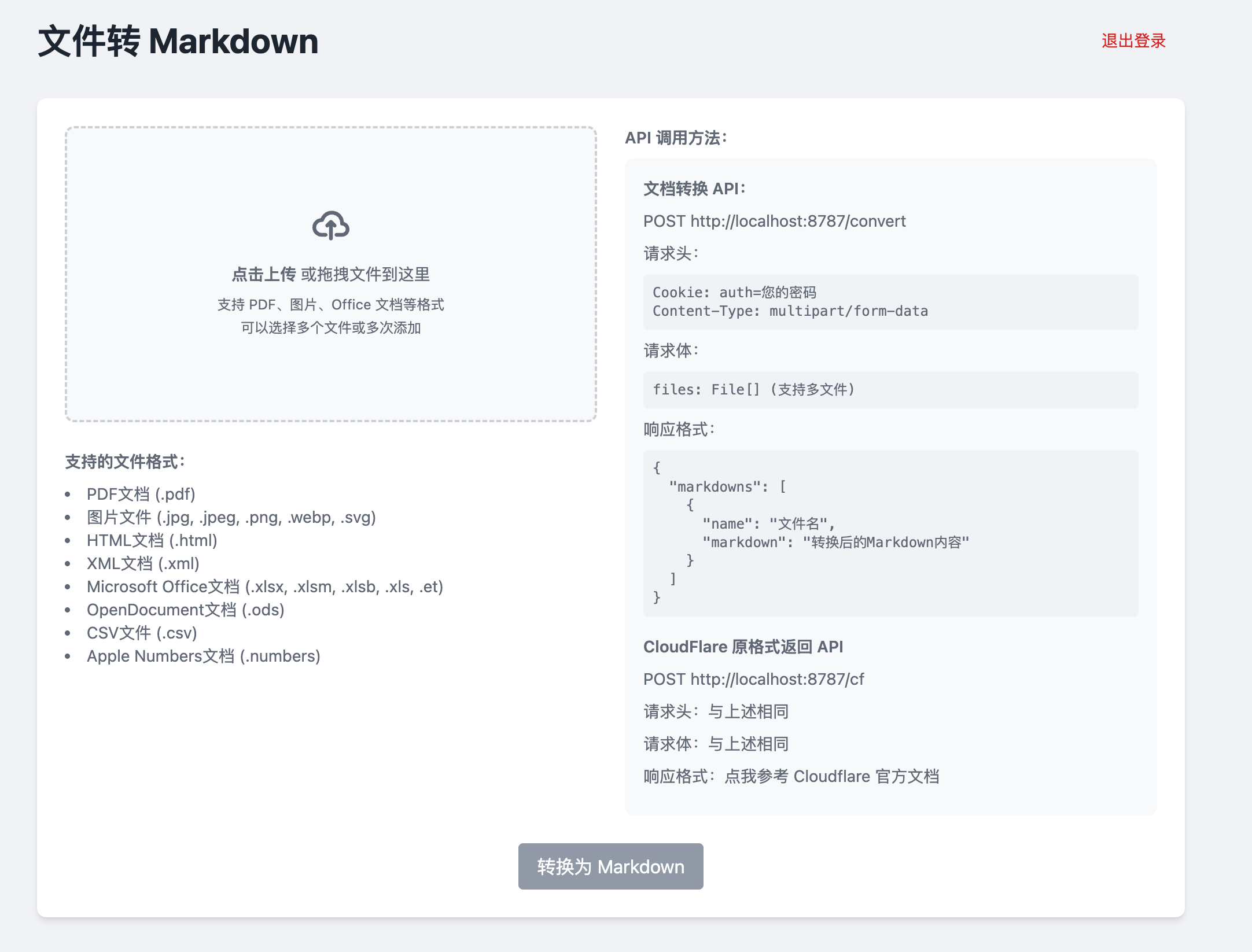
Workers AIに基づいて、無料で複数のファイルをMarkdown形式に変換する综合介绍 serverless-markdown-convertor 是一个免费的开源工具,基于 Cloudflare Worker 和 Workers AI 开发,能将多种文件转换为 Markdow...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前0723
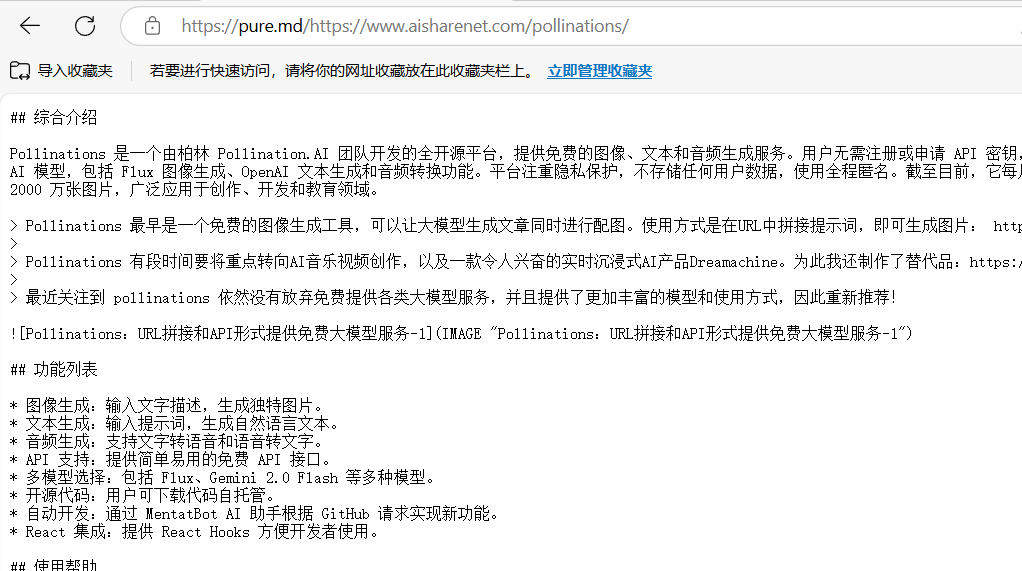
pure.md:URLの前に "pure.md/"を挿入して、きれいなテキストを取り出す。一般的な紹介 pure.mdはAIエージェントや開発者のためのツールで、ウェブコンテンツやファイルを素早くMarkdown形式に変換することに重点を置いています。プロキシサービスによるクローラー対策の制限を回避し、ウェブページのコアデータを抽出し、クリーンなMarkdownを出力します。最新のAIツール# AIオープンサービス# ドキュメントの抽出とクリーニング4ヶ月前0707
Cloudsquid: ドキュメントをアップロードし、構造化データのインテリジェントな抽出のための要件を記述する。综合介绍 Cloudsquid 是一家 2023 年成立于德国柏林的公司,专注于用人工智能简化文件处理。它的核心产品是一个在线数据提取平台,用户只需上传 PDF、图片、音频、视频等文件,简单说明需要提...最新のAIツール# ドキュメントの抽出とクリーニング4ヶ月前0689
PDF Craft: PDFスキャン文書からMarkdownへのオープンソースツール综合介绍 PDF Craft 是一个开源工具,专为扫描书籍的PDF设计,能将其转换为Markdown格式。它由 oomol-lab 开发,托管在 GitHub 上,适合喜欢整理电子书的用户。工具通过本...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング4ヶ月前0874
Supametas.AI:非構造化データをLLMの高可用性データに抽出する包括的な紹介 Supametas.AIは、ウェブページ、文書、音声、動画などの乱雑なデータを、AIが利用できる構造化データに整理することに特化したデータ処理プラットフォームです。ウェブリンク、API、ローカルファイルなど複数のソースからデータを収集し、JSONとして出力することができます。最新のAIツール# AIオープンサービス# ドキュメントの抽出とクリーニング4ヶ月前0691
MarkPDFDown: マルチモーダルモデルに基づくPDFからMarkdownへの変換综合介绍 MarkPDFDown 是一个开源工具。它利用多模态大语言模型,把 PDF 文件转为 Markdown 格式。开发者是 GitHub 用户 jorben。这个工具的目标很简单:让 PDF 文...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前0891
SmolDocling:少量で効率的な文書処理のための視覚言語モデル综合介绍 SmolDocling 是由 ds4sd 团队与 IBM 合作开发的一个视觉语言模型(VLM),基于 SmolVLM-256M 打造,托管在 Hugging Face 平台。它体积小,只有 ...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング4ヶ月前0848
Markdownify MCP Server: MCPプロトコルに基づき、様々なコンテンツをMarkdownフォーマットに変換します。一般的な紹介 Markdownify MCPサーバーはモデルコンテキストプロトコルに基づいたオープンソースツールで、開発者のZach CaceresによってGitHubでホストされています ...最新のAIツール# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング4ヶ月前0953
Firecrawl MCPサーバー: FirecrawlベースのWebクローラーMCPサービス概要 Firecrawl MCP Serverは、MendableAIによって開発されたオープンソースツールで、モデルコンテキストプロトコル(MCP)プロトコルの実装に基づき、Firecrawl A...最新のAIツール# AI Java オープンソースプロジェクト# MCPサービス# ドキュメントの抽出とクリーニング4ヶ月前01.1K
フライング・パドル PP-TableMagic: 複雑なテーブルの構造化情報抽出表格识别的目标是解析图片中的表格,准确识别表格结构和单元格位置,并将其还原为结构化的表格格式(例如 HTML)。在当今信息化时代,大量重要的表格数据仍以非结构化状态存在(如扫描文档中的信息统计表图片...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前0854
ミストラルOCR:94.89%総合精度、1000ページ/30秒、わずか1ドル在人类文明的历史长河中,每一次信息获取和解析方式的飞跃,都深刻地推动着社会进步。从远古的象形文字,到便携的纸莎草,再到后来出现的印刷术以及当今的数字化浪潮,每一次技术革新都极大地拓展了人类知识的传播范...最新のAIツール# AIオープンサービス# OCR# ドキュメントの抽出とクリーニング4ヶ月前0769
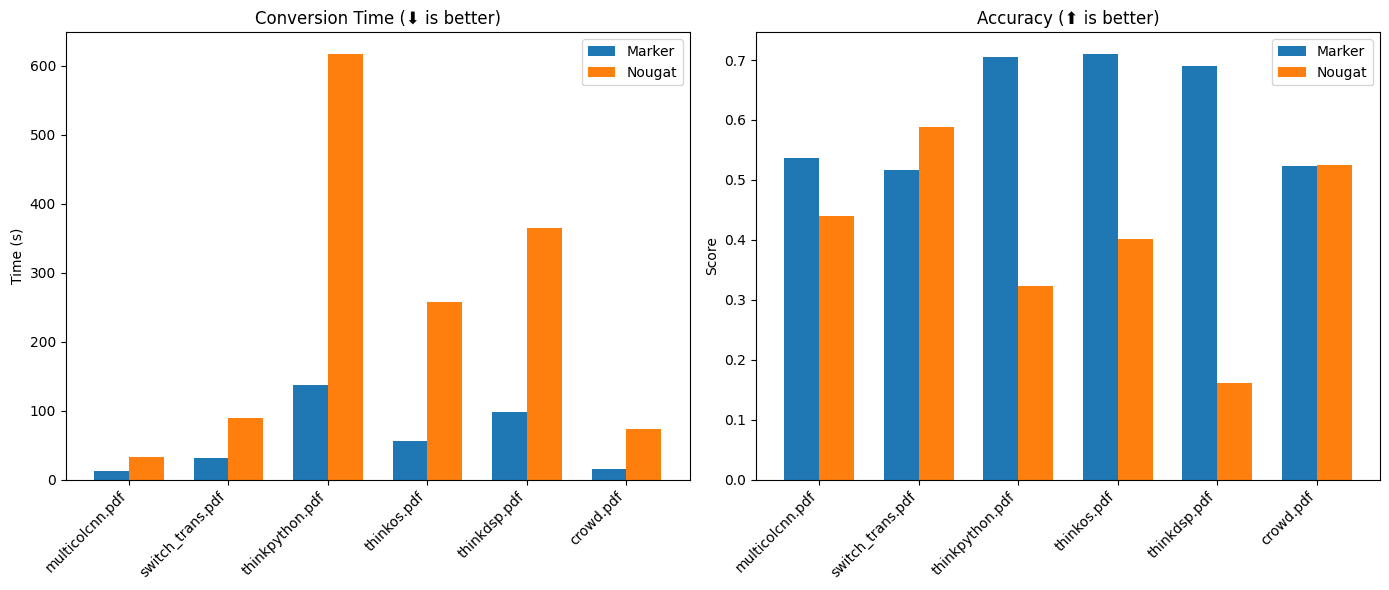
Marker:PDFをMarkdownに素早く変換するオープンソースツール综合介绍 Marker 是一个基于深度学习的文档处理工具,旨在将 PDF 文件快速准确地转换为 Markdown 格式。它支持多种文档类型,特别优化了书籍和科学论文的转换。Marker 能够去除页眉页...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.9K
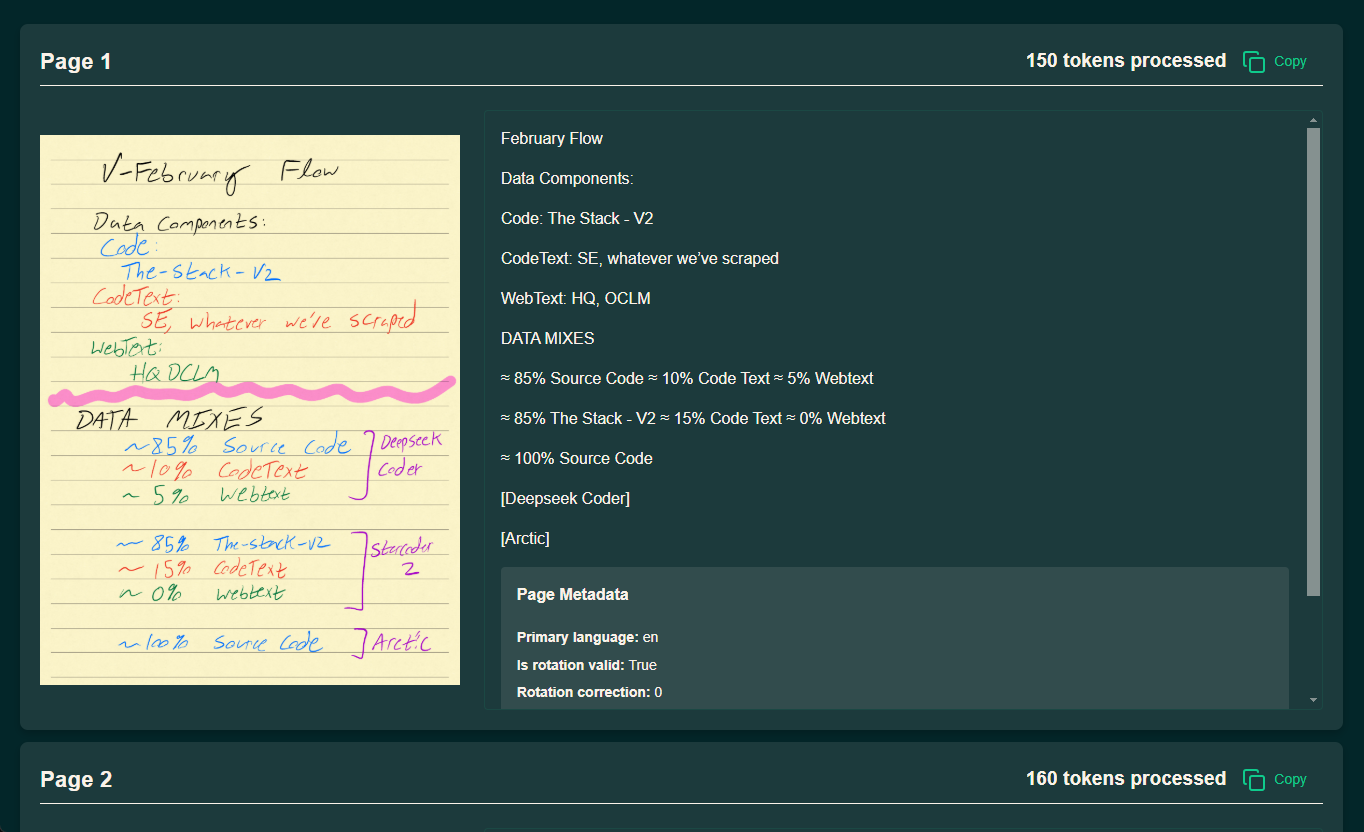
olmOCR: PDF 文書のテキスト変換、表、数式、手書き内容の認識のサポート综合介绍 olmOCR 是由 Allen Institute for Artificial Intelligence (AI2) 的 AllenNLP 团队开发的一款开源工具,专注于将 PDF 文件转...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.1K