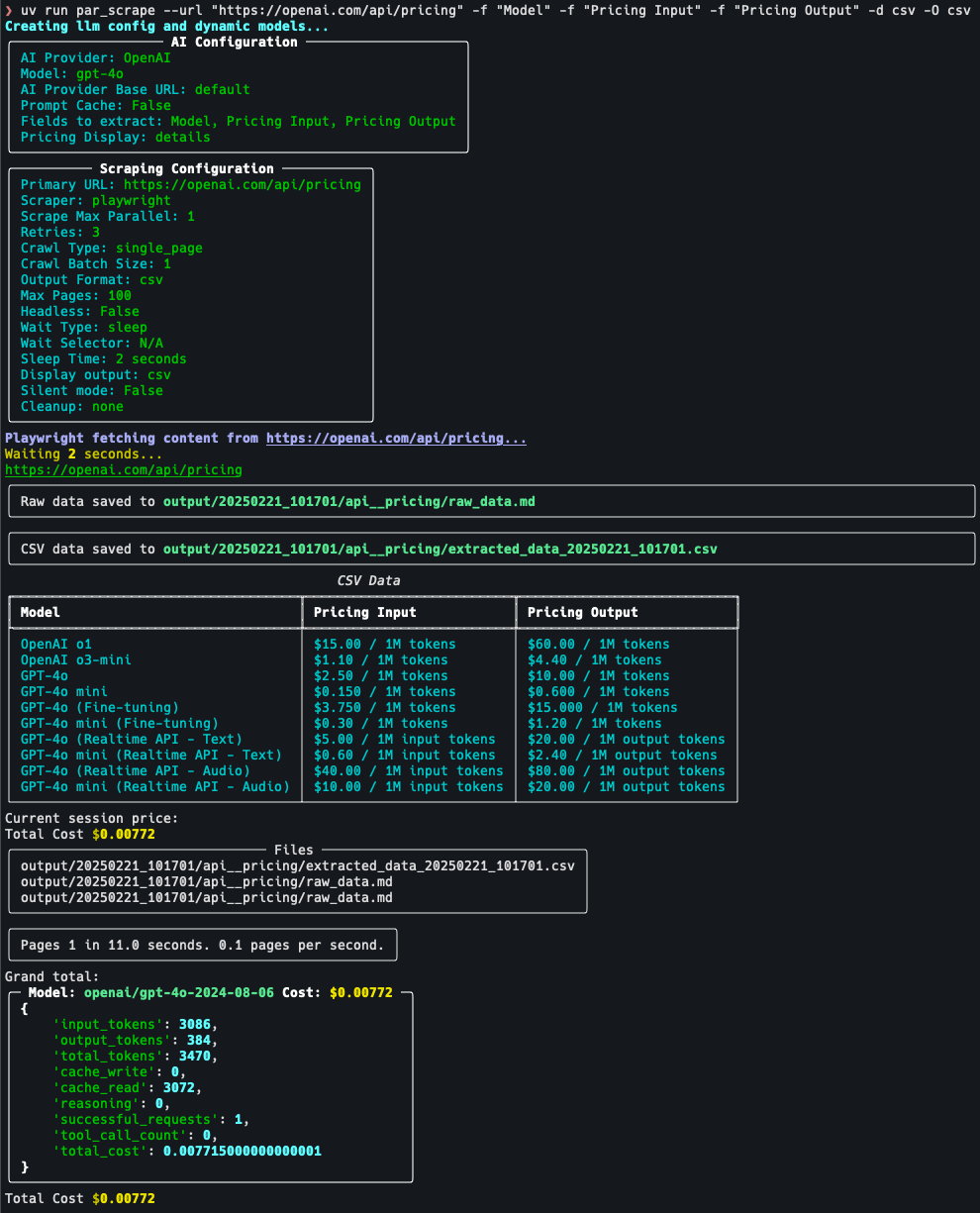
par_scrape: ウェブデータをインテリジェントに抽出するクローラーツール综合介绍 par_scrape 是一个基于 Python 的开源网页爬虫工具,由开发者 Paul Robello 在 GitHub 上推出,旨在帮助用户从网页中智能提取数据。它整合了 Selenium...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング3ヶ月前05840
PDF-Extract-Kit:オープンソースツールのPDFコンテンツの複雑な構造を抽出する综合介绍 PDF-Extract-Kit 是一个由 OpenDataLab 团队开发的开源项目,专注于从复杂多样的 PDF 文档中高效提取高质量内容。它集成了先进的文档解析技术,支持布局检测、公式识别...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング3ヶ月前07560
Crawl4LLM:LLM事前学習のための効率的なウェブクローリングツール包括的な紹介 Crawl4LLMは清華大学とカーネギーメロン大学によって共同開発されたオープンソースプロジェクトであり、大規模モデル(LLM)の事前学習のためのウェブクローリングの効率最適化に焦点を当てている。高品質なウェブページデータをインテリジェントに選択することで、非効率なクロールを大幅に削減し、本来1...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング3ヶ月前05790
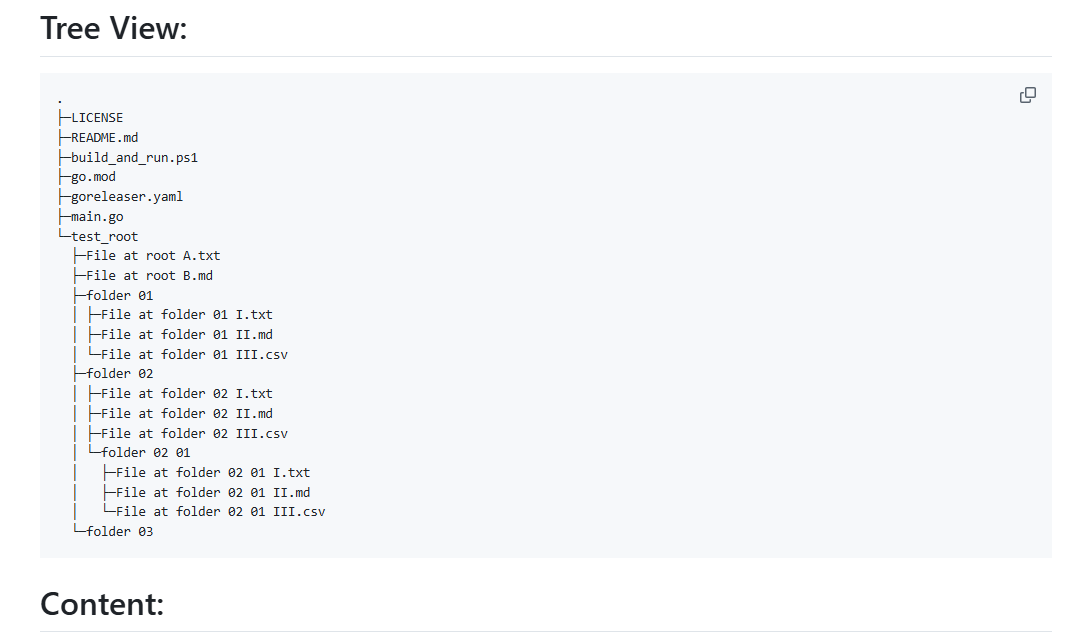
CodeWeaver: コード構造とコンテンツから自動的にMarkdownドキュメントを生成します。一般的な紹介 CodeWeaverは、コード・ライブラリを単一の見やすいMarkdownドキュメントに編むために設計されたコマンドライン・ツールです。ディレクトリを再帰的にスキャンし、各ファイルの内容をコードブロックに埋め込むことで、プロジェクトのファイル階層を構造化した表現を生成します。このツールは...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前05230
Kreuzberg: あらゆる文書からテキストを抽出するオープンソースツール一般的な紹介 Kreuzbergは、PDFファイルからのテキスト抽出を簡素化するためのライブラリで、シンプルで手間のかからないテキスト抽出ソリューションを提供するように設計されています。このライブラリは、特にRAG(Retrieval-Augmented Generatio...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前07040
講師:大規模言語モデルの構造化出力ワークフローを簡素化するPythonライブラリ概要 Instructorは、大規模言語モデル(LLM)からの構造化出力を処理するために設計された人気のあるPythonライブラリです。Pydanticをベースに構築されており、データを管理するためのシンプルで透過的、かつユーザーフレンドリーなAPIを提供します。最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前07060
AIファンクション:入力コンテンツを構造化された出力に変換する(API)サービス包括的な紹介 Weco AI Functionsは、ユーザーが迅速にAIファンクションを構築し、展開できるように設計された強力なプラットフォームです。タスクを記述するだけで、ユーザーはA/Bテストや観察モニタリングで構造化された出力パターンを生成できます。このプラットフォームは、ノーコードのプロトタイピングをサポートします。最新のAIツール# AIオープンサービス# ドキュメントの抽出とクリーニング4ヶ月前07830
アウトライン: 正規表現、JSON、Pydanticモデルによる構造化テキスト出力の生成综合介绍 Outlines 是一个由 dottxt-ai 开发的开源库,旨在通过结构化文本生成来提升大语言模型(LLM)的应用能力。该库支持多种模型集成,包括 OpenAI、transformers...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前01.1K0
zChunk: Llama-70Bに基づく一般的な意味的チャンキング戦略包括的な紹介 zChunkは、ZeroEntropyによって開発された、一般的なセマンティック・チャンキングのソリューションを提供する新しいチャンキング戦略です。このストラテジーはLlama-70Bモデルに基づいており、チャンクの生成を促すことでドキュメントのチャンキングプロセスを最適化し、情報検索を高いレベルで維持することを保証します。最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前05880
Chonkie: 軽量なRAGテキストチャンキングライブラリ综合介绍 Chonkie 是一个轻量级且高效的 RAG(Retrieval-Augmented Generation)文本切块库,旨在帮助开发者快速、简便地对文本进行分块处理。该库支持多种分块方法,包...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前01.3K0
パルス:文書処理とデータ抽出のためのビジネスソリューションPulseは、文書処理とデータ抽出に特化したインテリジェントなプラットフォームで、企業や開発者がさまざまな複雑な文書を効率的に解析・処理できるように設計されています。高度なコンピュータビジョンとマルチモーダル処理技術により、Pulse はテキスト、画像、表、その他多くのデータから正確にデータを抽出することができます。最新のAIツール# ドキュメントの抽出とクリーニング4ヶ月前06950
ロウフィル:文書からの構造化情報の一括抽出と自動分析概要 Rowfillは、ナレッジワーカーのために設計されたオープンソースの文書処理プラットフォームです。高度な人工知能技術を使用して、複雑な文書、画像、PDFからデータを抽出、分析、処理します。Rowfillは、Large Language Model(LLM)とOpe...最新のAIツール# AI Java オープンソースプロジェクト# AIデータ分析# ドキュメントの抽出とクリーニング4ヶ月前06980
PPTX2MD: PPTXファイルをMarkdownに変換する特別なツール概要 PPTX2MDは、PowerPointのPPTXファイルをMarkdown形式に変換するために設計されたオープンソースツールです。GitHubユーザーのssine氏によって開発されたこのツールは、見出し、リスト、テキストフォーマット(例:太字、斜体、色、スーパー...)を保持することをサポートしています。最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前08730
Doc2X:文書画像式認識・変換ツール、マルチフォーマット変換と高精度翻訳をサポート综合介绍 Doc2X 是一款功能强大的文档图片公式识别与转换工具,致力于提供高效智能的文档处理解决方案。无论是学术科研论文、教辅书籍、企业文档还是财报研报,Doc2X 都能精准识别 PDF 中的表格和...最新のAIツール# AIオープンサービス# AI翻訳# ドキュメントの抽出とクリーニング4ヶ月前09510
Repomix:大規模モデル検索用にコードベースをテキストファイルにパッケージ化概論 Repomix(以前はRepopackとして知られていた)は、コードベース全体を単一のAIフレンドリーなファイルにパッケージ化するために設計されたオープンソースツールです。このツールにより、開発者は自分のコードベースを大規模な言語モデル(ClaudeやChat...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前01.2K0
Yek: git リポジトリのテキストファイルを読み込んで、大規模なモデルのために素早くチャンキングする。一般的な紹介 Yekは、リポジトリやディレクトリからテキストファイルを読み込んでチャンキングし、大規模言語モデル(LLM)で使用するためにシリアライズするRustベースの高速ツールです。このツールはデフォルトで .gitignore ルールを使って不要なファイルをスキップし、...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前09730
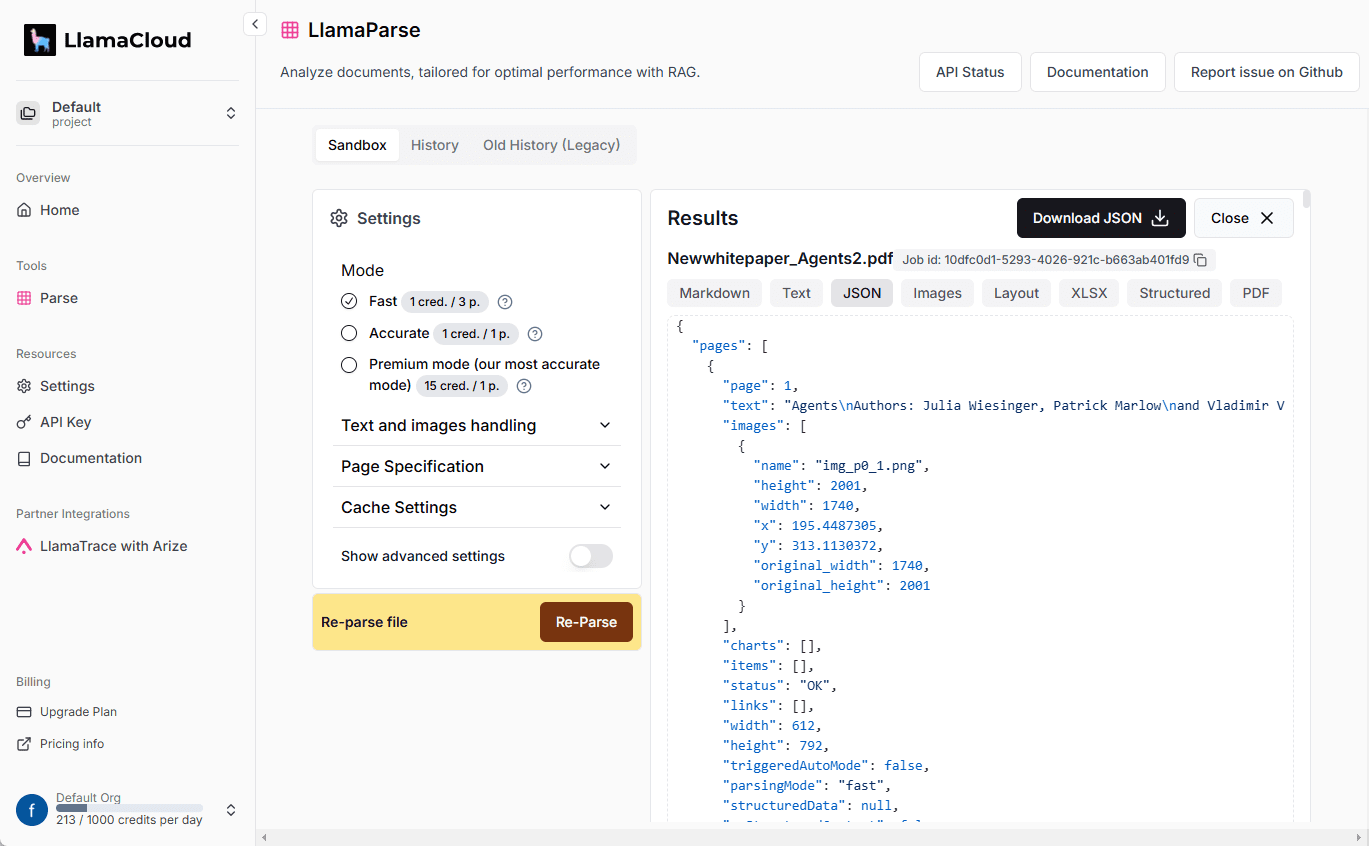
LlamaParse: Llamaindexによる高品質な文書解析とデータ抽出サービス(1日1000ページ無料)。包括的な紹介 LlamaParseは、PDF、PowerPoint、Word文書、スプレッドシートなどの複雑な文書を処理し、構造化データに変換できる強力な文書解析ツールです。最新のAIツール# AIオープンサービス# ドキュメントの抽出とクリーニング4ヶ月前09780
UnDatas.IO: さまざまな種類の非構造化データを正確に解析するAPIサービス(有料)包括的な紹介 UnDatas.IOは、非構造化データの解析と処理に特化したプラットフォームです。高度な技術を駆使して、ドキュメントのレイアウトを自動的に認識し、表、画像、数式、テキストを分類して、データ処理プロセスを大幅に簡素化します。このプラットフォームは、データの並べ替えにかかる時間を大幅に節約するだけでなく...最新のAIツール# AIオープンサービス# ドキュメントの抽出とクリーニング4ヶ月前08400
Zerox: PDF、DOCX、Markdownへの画像変換、ビジュアルモデル高精度OCR一般的な紹介 Zeroxは、ビジュアルモデルを通してPDF、DOCX、画像やその他のドキュメントをMarkdown形式に変換するために設計されたオープンソースプロジェクトです。このプロジェクトはgetomni-aiチームによって開発され、シンプルで効率的なOCR(光学式文字認識)ソリューションを提供します。最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前01K0