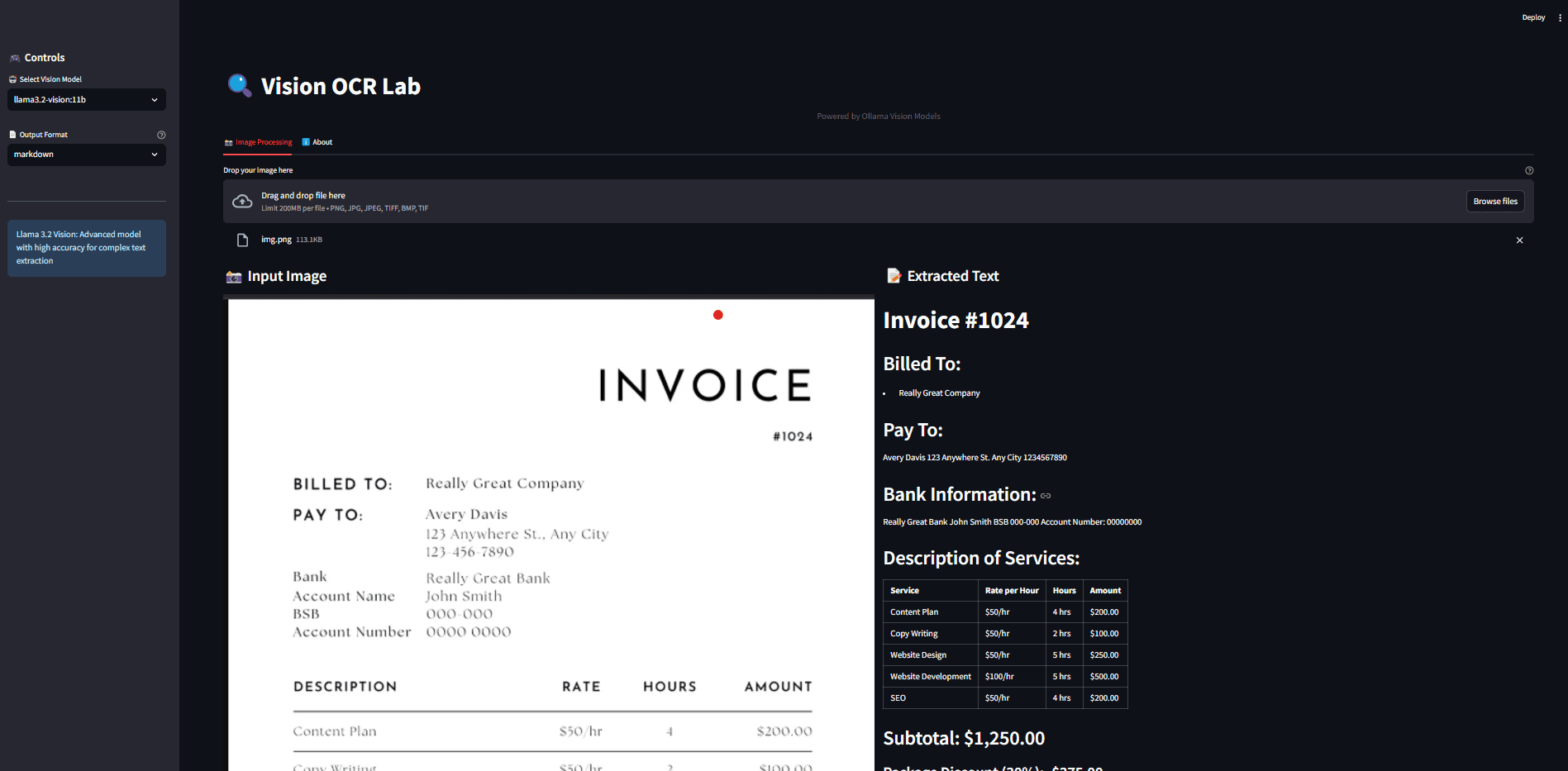
Ollama OCR: Ollamaの視覚モデルを使った画像からのテキスト抽出综合介绍 Ollama OCR是一个强大的光学字符识别(OCR)工具包,它利用Ollama平台提供的最先进视觉语言模型来从图像中提取文本。该项目既可作为Python包使用,也提供了用户友好的Strea...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング6ヶ月前02.2K
Docling:様々なフォーマットのドキュメントをサポート MarkdownやJSONへの解析とエクスポート PDFサポート OCR包括的な紹介 Doclingは、PDF、DOCX、PPTX、XLSX、画像、HTML、AsciiDocおよびMarkdownを含む幅広い文書形式をサポートする強力な文書解析およびエクスポートツールです。最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング7ヶ月前02.1K
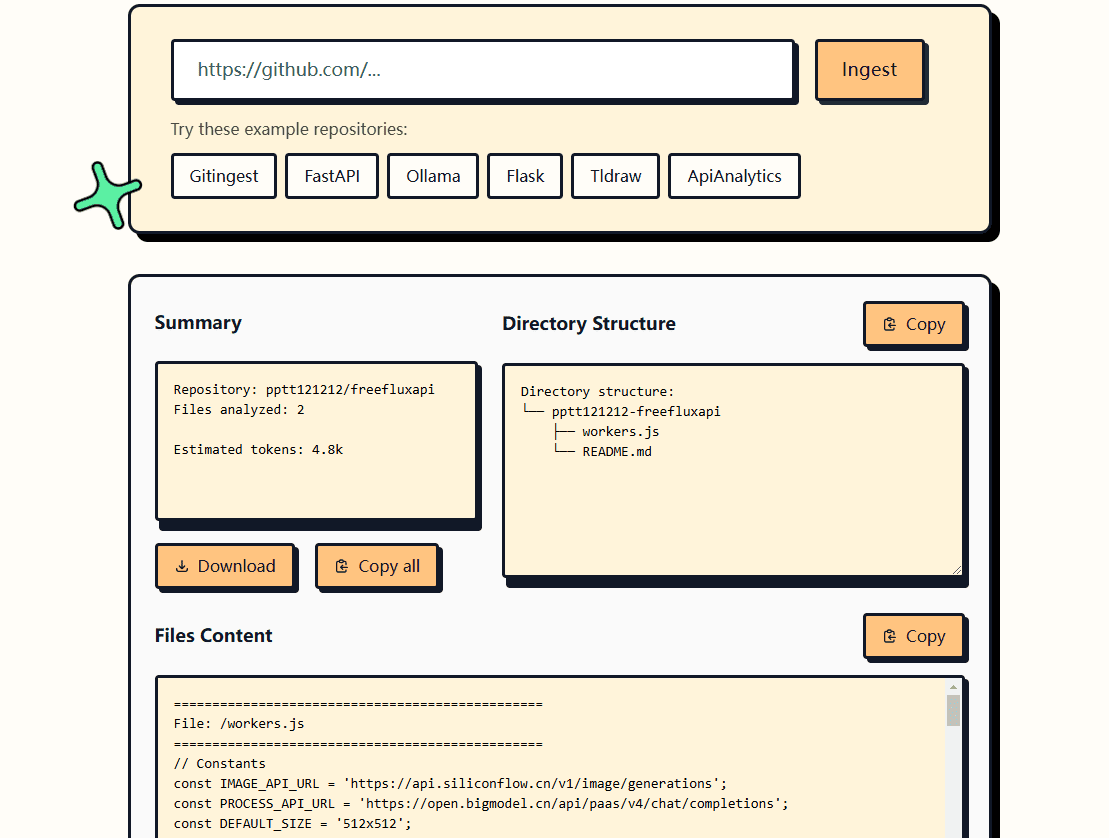
GitIngest: GithubのコードリポジトリをLLMの理解に適したテキストに素早く変換概要 GitIngestは、GitHubのコードリポジトリをLarge Language Model (LLM)のヒントに適したテキストに変換するためのオープンソースツールです。簡単な操作で、あらゆるGitHubリポジトリの内容を抽出し、LLMヒントに適合するように整形することができます。最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング7ヶ月前01.9K
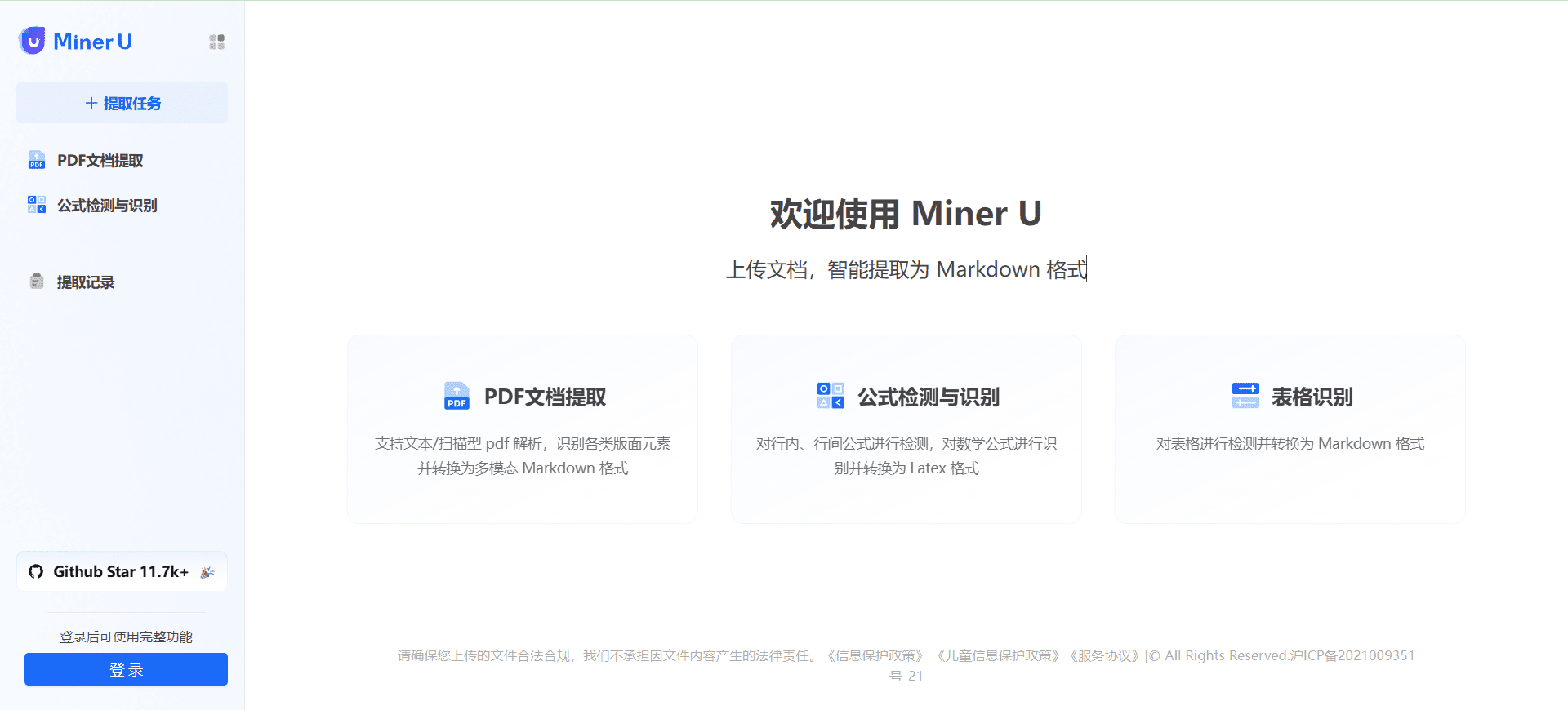
MinerU: PDFドキュメントの抽出とマルチモーダルMarkdownフォーマットへの変換、電子書籍OCRスキャンのサポート综合介绍 MinerU是由上海人工智能实验室OpenDataLab团队开发的一款开源数据提取工具,专注于从复杂的PDF文档、网页和电子书中高效提取内容。它能够将包含图片、公式、表格等元素的多模态PDF...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング10ヶ月前01.9K
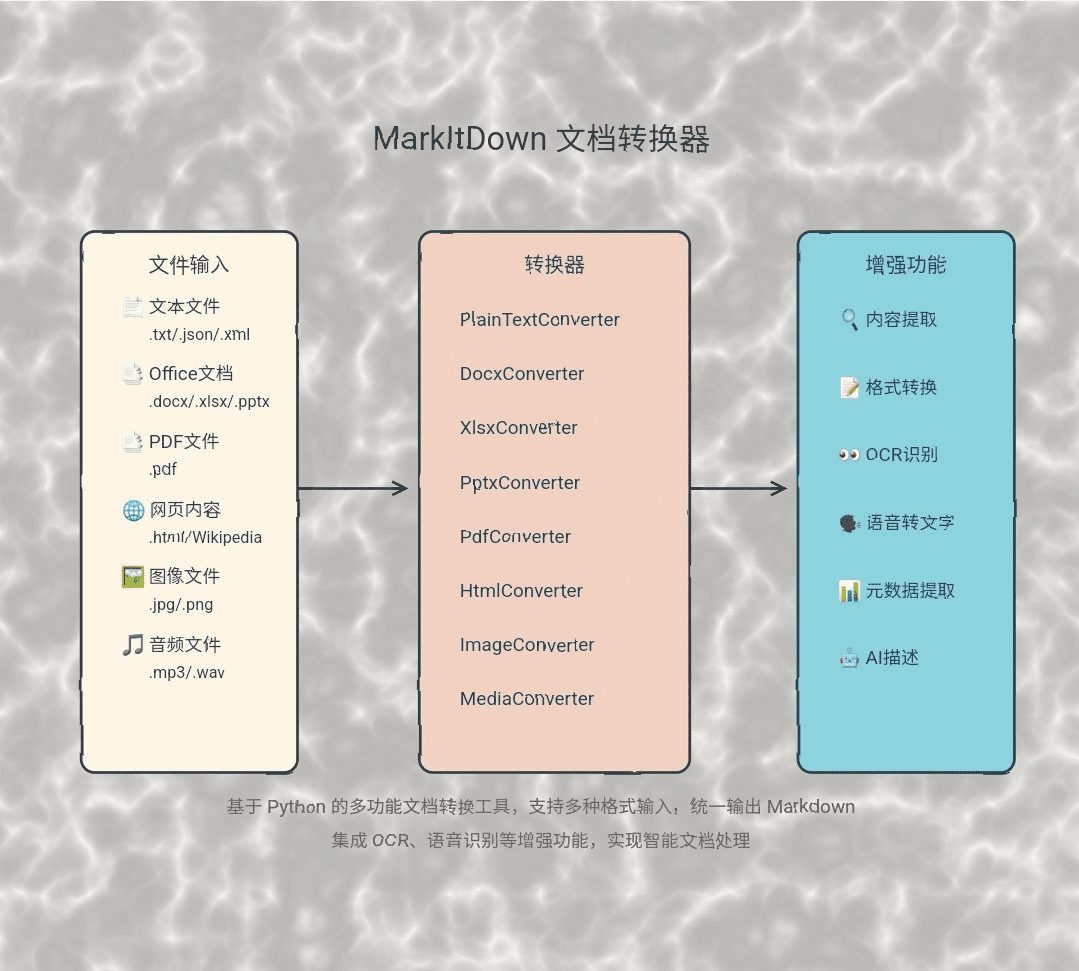
MarkItDown:Microsoftドキュメントインテリジェント変換ツール、様々なファイルをMarkdown形式に変換综合介绍 MarkItDown是由微软开发的一个Python工具,旨在将各种文件和办公文档转换为Markdown格式。该工具支持多种文件类型,包括PDF、PowerPoint、Word、Excel、图...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング7ヶ月前01.9K
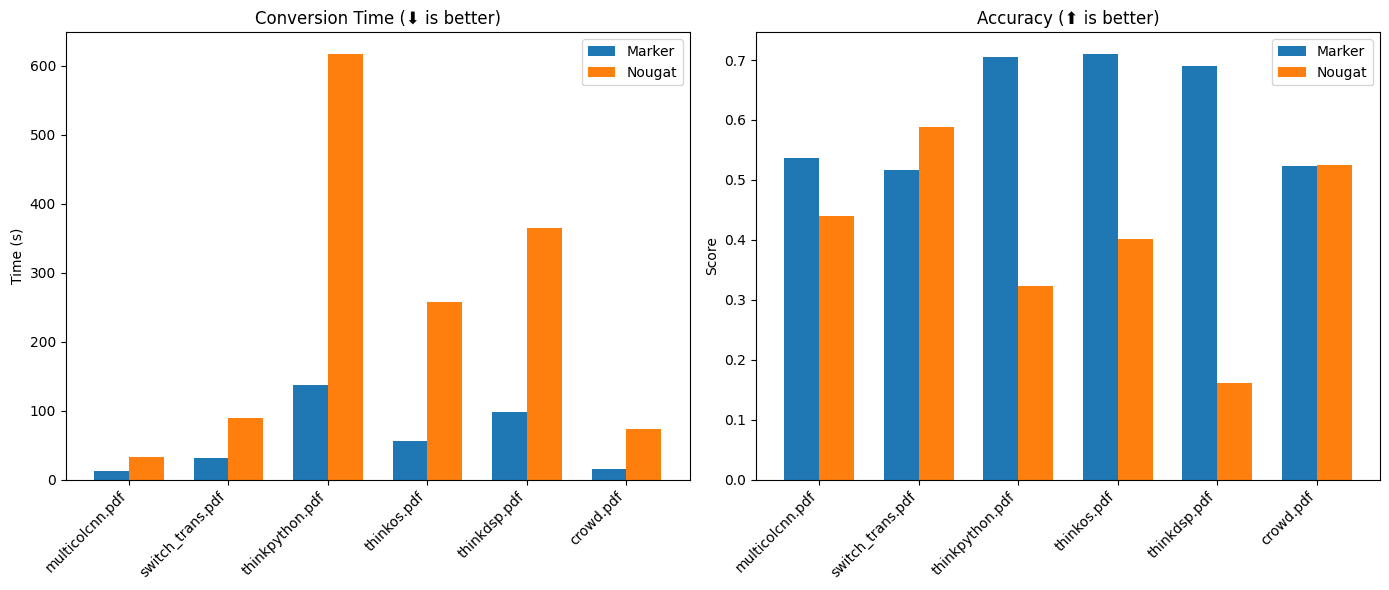
Marker:PDFをMarkdownに素早く変換するオープンソースツール综合介绍 Marker 是一个基于深度学习的文档处理工具,旨在将 PDF 文件快速准确地转换为 Markdown 格式。它支持多种文档类型,特别优化了书籍和科学论文的转换。Marker 能够去除页眉页...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.9K
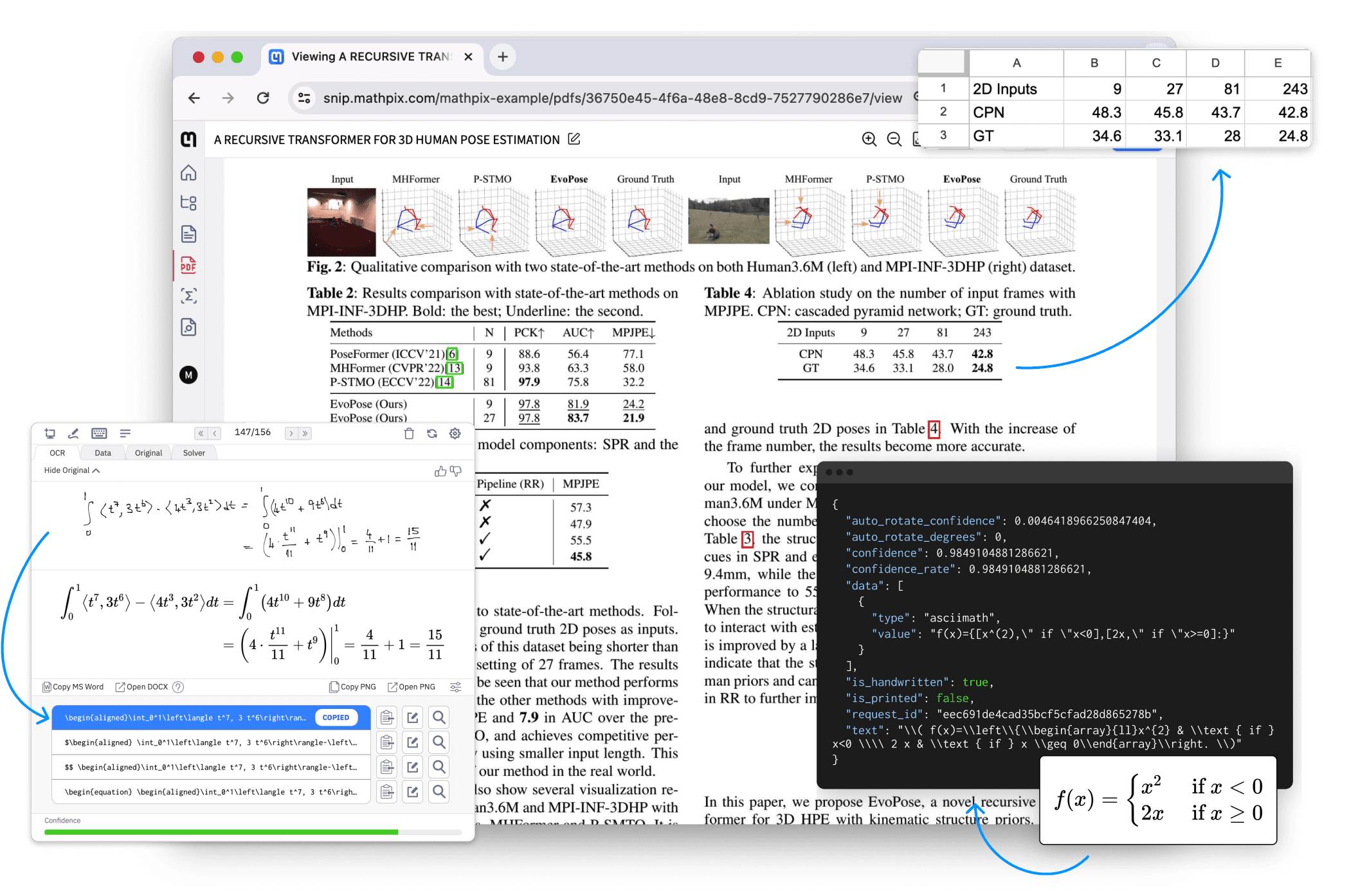
Mathpix:PDFと画像ドキュメントの構造変換ソフトウェア、マルチターミナルをサポート概要 Mathpixは、研究者、開発者、企業向けに設計された、強力なAI駆動型ドキュメント自動化ツールです。Mathpixは、PDFや画像を迅速かつ正確に、検索可能、エクスポート可能、機械可読テキストに変換します。最新のAIツール# AIオープンサービス# ドキュメントの抽出とクリーニング11ヶ月前01.8K
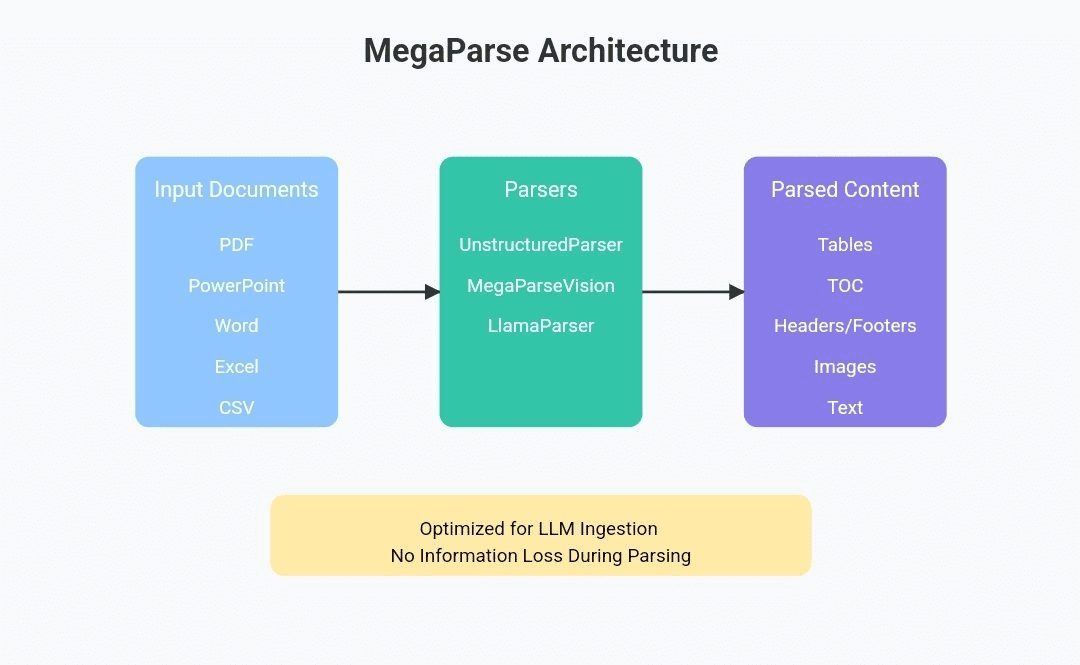
MegaParse:各タイプのドキュメントをLLMで利用可能なデータに解析し、表や写真などドキュメント内のすべての情報をそのまま保存する。综合介绍 MegaParse 是一个强大且多功能的文件解析工具,专为大语言模型(LLM)的数据处理优化而设计。无论是处理文本、PDF、PowerPoint 演示文稿还是 Word 文档,MegaPar...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング7ヶ月前01.7K
Reader API: ウェブコンテンツ抽出ツール、HTMLからMarkdownへの変換综合介绍 Jina AI的Reader项目是一个开源工具(Reader 开源地址),可将任何URL通过添加前缀https://r.jina.ai/转换成适合大型语言模型(Large Languag...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング10ヶ月前01.6K
Datalab:専用のOCR認識AIモデル、PDF to Markdown(オープンソース/API)综合介绍 Datalab 提供了一系列先进的AI模型,专注于OCR、布局分析、PDF转Markdown等功能。这些模型不仅性能卓越,而且易于使用,并且是开源的。平台上的Marker模型可以快速准确地将...最新のAIツール# AIオープンサービス# AI Java オープンソースプロジェクト# OCR8ヶ月前01.6K
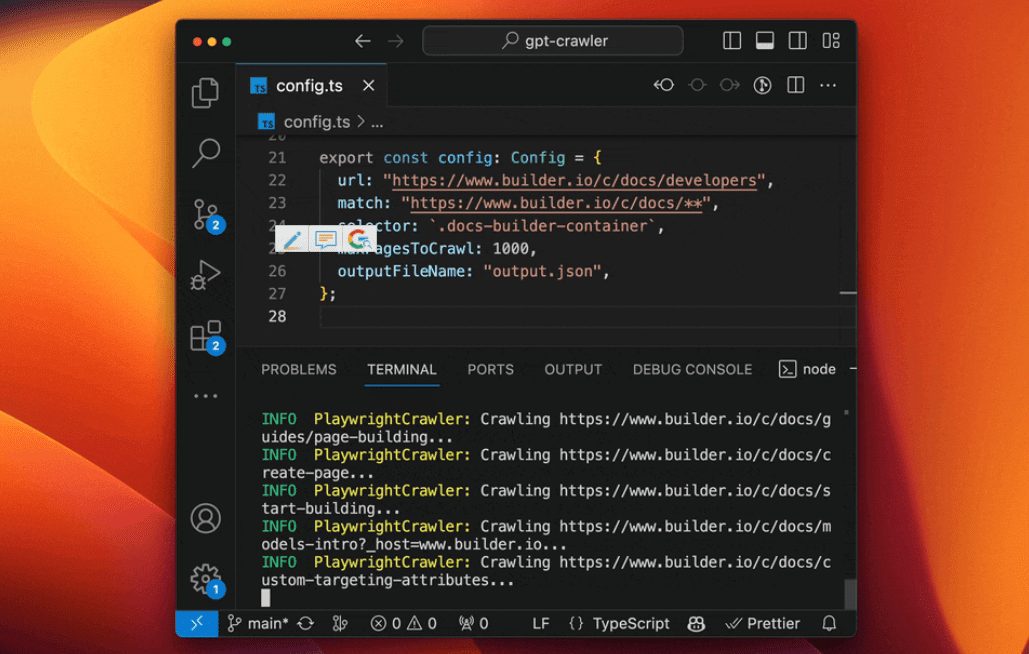
GPT-Crawler: ウェブサイトコンテンツを自動的にクロールして知識ベースドキュメントを生成综合介绍 GPT-Crawler 是由 BuilderIO 团队开发的一个开源工具,托管在 GitHub 上。它通过输入一个或多个网站 URL,爬取页面内容,生成结构化的知识文件(output.jso...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング1ヶ月前01.5K
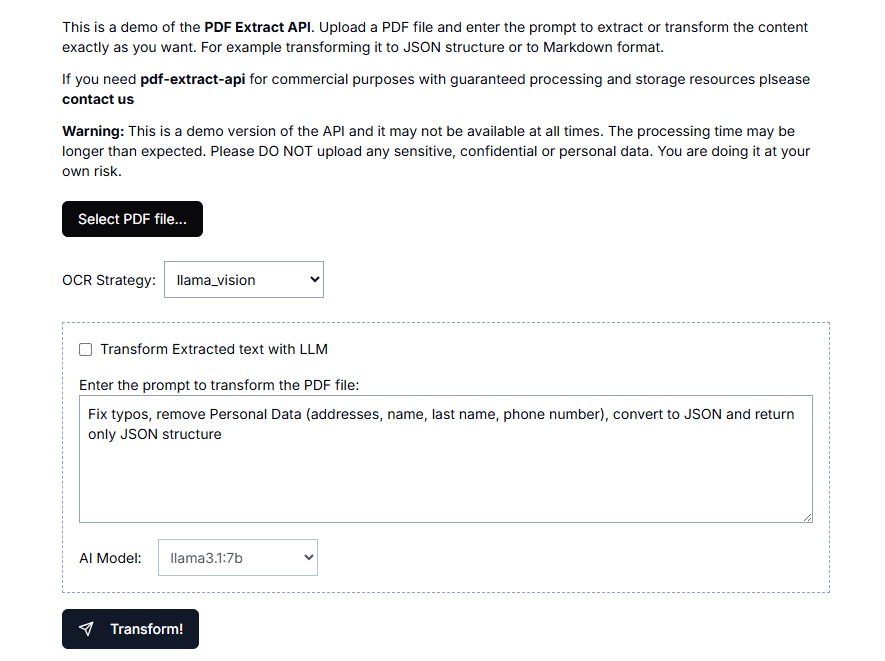
テキスト抽出 API (text-extract-api): テキスト情報の視覚的抽出、匿名化 PDF 抽出ツール包括的な紹介 テキスト抽出API(text-extract-api)は、さまざまな文書形式(PDF、Word、PPTXなど)からコンテンツを抽出し、解析するために設計された強力なツールです。このAPIは、最先端の光学式文字認識(OCR)技術とOl...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング6ヶ月前01.5K
Chonkie: 軽量なRAGテキストチャンキングライブラリ综合介绍 Chonkie 是一个轻量级且高效的 RAG(Retrieval-Augmented Generation)文本切块库,旨在帮助开发者快速、简便地对文本进行分块处理。该库支持多种分块方法,包...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.5K
非構造化:オープンソースの非構造化ドキュメントの前処理、非構造化データ処理ツール综合介绍 Unstructured-IO 提供了一系列开源组件,用于处理和预处理图像和文本文档,如 PDF、HTML、Word 文档等。其主要目标是简化和优化数据处理工作流程,特别是为大语言模型(LL...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング11ヶ月前01.4K
Parsio: PDF、電子メール、その他のドキュメントから主要な構造化データを自動的に抽出します。综合介绍 Parsio 是一款基于 AI 技术的文档和邮件数据提取工具,能够自动从 PDF、电子邮件及其他文档中提取结构化数据。该平台提供强大的 PDF 解析器和 OCR 功能,支持多种文档类型,包括...最新のAIツール# ドキュメントの抽出とクリーニング8ヶ月前01.4K
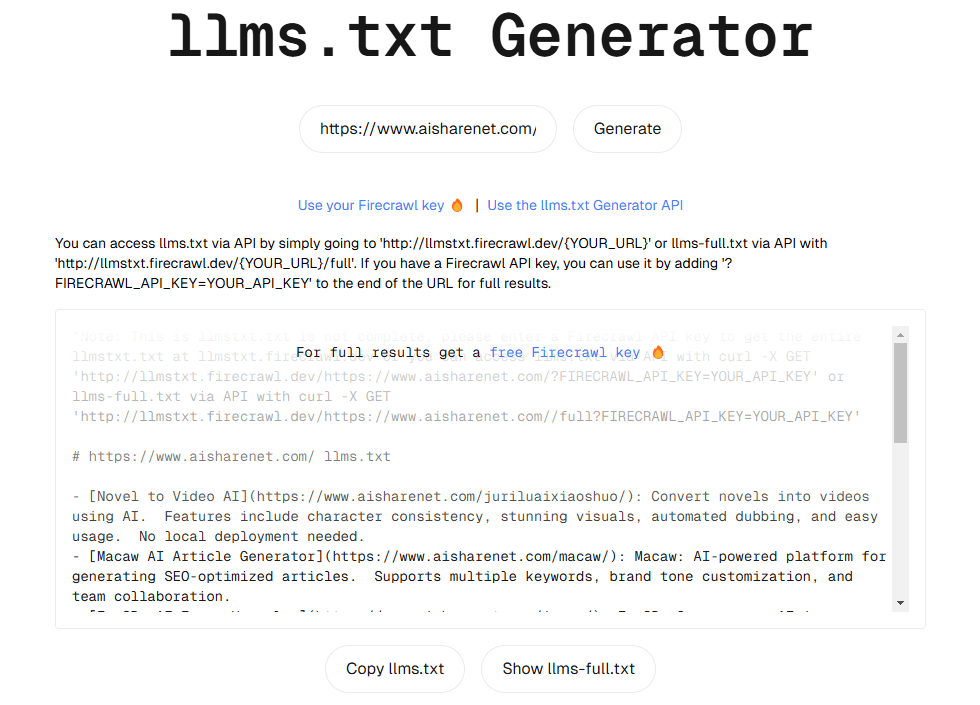
llms.txt Generator: Webサイトのコンテンツを素早くキャプチャし、LLMトレーニング用テキストデータセットを生成します。综合介绍 llmstxt-generator 是一个专业的网站内容提取和整合工具,专门为大语言模型(LLM)的训练和推理准备高质量文本数据集。该工具由 Mendable AI 开发,采用 @firec...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング6ヶ月前01.4K
Repomix:大規模モデル検索用にコードベースをテキストファイルにパッケージ化概論 Repomix(以前はRepopackとして知られていた)は、コードベース全体を単一のAIフレンドリーなファイルにパッケージ化するために設計されたオープンソースツールです。このツールにより、開発者は自分のコードベースを大規模な言語モデル(ClaudeやChat...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング6ヶ月前01.4K
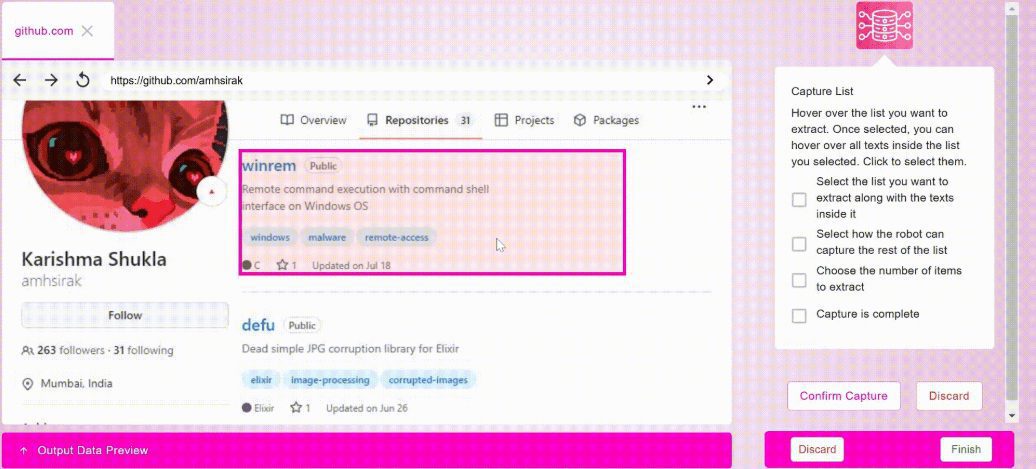
Maxun:ウェブデータを自動的にクロールし、APIやスプレッドシートに変換するオープンソースのコード不要プラットフォーム综合介绍 Maxun是一个开源的无代码网页数据提取平台,用户可以在几分钟内训练机器人,自动抓取网页数据并将其转换为API或电子表格。该平台支持分页和滚动,能够适应网站布局的变化,提供强大的数据抓取功能...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング6ヶ月前01.4K
Doc2X:文書画像式認識・変換ツール、マルチフォーマット変換と高精度翻訳をサポート包括的な紹介 Doc2Xは、強力な文書画像式認識と変換ツールで、効率的でインテリジェントな文書処理ソリューションを提供することを約束します。学術研究論文、教科書、企業文書、財務報告書など、Doc2XはPDFの表と数式を正確に認識することができます。最新のAIツール# AIオープンサービス# AI翻訳# ドキュメントの抽出とクリーニング6ヶ月前01.4K